|
В этом разделе описываются встроенные функции
HomeLisp, принадлежащие "классическому" Лиспу. Следует
отметить, что разработчик использовал известные понятия
SUBR/FSUBR в несколько ином смысле, нежели Лавров и
Силагадзе в своей замечательной книге
[1]. В HomeLisp
у функций типа SUBR все аргументы вычисляются, но
допускаются функции с переменным числом аргументов,
тогда как у Лаврова и Силагадзе количество аргументов функций
типа SUBR должно быть фиксированным. У функций
типа FSUBR вычисляются не все аргументы (какие
именно - зависит от конкретной функции). Таким образом, в
HomeLisp функции PLUS, TIMES, MAX принадлежат к
типу SUBR (тогда, как у Лаврова и Силагадзе эти функции
принадлежат к типу FSUBR, т.к. они имеют неопределенное
число аргументов).
Функции, возвращающие логические значения T или
Nil, называются предикатами. Некоторые
предикаты предназначены для проверки типа своего аргумента
(FIXEDP, FLOATP и т.д.). В Лиспе принято, что
имена таких предикатов оканчиваются буквой p.
Ниже довольно часто используется термин
"квотирование". Смысл его отличается от
общеупотребительного: квотировать - это не выдавать строго
отмеренное количество чего-либо, а применять к S-выражению
функцию QUOTE. Квотирование атома a, означает
запись (QUOTE a) или, что равнозначно - 'a.
Далее приводится описание всех встроенных в
HomeLisp функций. При этом
звездочкой (*) выделены функции,
отсутствующие в реализации, описанной в книге Лаврова и
Силагадзе.
Если та или иная функция реализована только в 11-м или только
в 13-м ядре, то номер ядра указывается в скобках
красным цветом.
Возможно также, что некоторые функции ведут себя по-разному в составе
11-го и 13-го ядер. Эти моменты комментируются явным образом.
|
Имя функции
|
Тип функции
|
К-во аргументов
|
Тип аргументов
|
Выполняемое действие
|
|
ABS
|
SUBR
|
1
|
FIXED, FLOAT
|
Вычисляет абс. Величину значения аргумента
|
|
ADD1
|
SUBR
|
1
|
FIXED, FLOAT
|
Прибавляет к значению аргумента единицу
|
|
AND
|
FSUBR
|
переменное
|
ANY
|
Последовательно вычисляет свои аргументы. Если значение
аргумента равно Nil, то функция возвращает Nil. Если значение всех аргументов
отлично от Nil, то функция возвращает значение последнего аргумента.
|
|
APPLY *
|
SUBR
|
2
|
1-ATOM или лямбда-выражение; 2-Список
|
Применяет первый аргумент (как функцию) к элементам списка, составляющим второй аргумент.
|
|
ATOM
|
SUBR
|
1
|
ANY
|
Проверяет, является ли значение аргумента атомом
|
|
BACKQUOTE * (13)
|
FSUBR
|
1
|
Список
|
Обратная блокировка (квотирование с частичным
вычислением)
|
|
BITSP
|
SUBR
|
1
|
BITS
|
Если значение аргумента имеет тип BITS,
функция возвращает T; в противном случае возвращается Nil.
|
|
BIT2FIX *
|
SUBR
|
1
|
BITS
|
Преобразует битовое значение в целое (FIXED)
|
|
CAAR
|
SUBR
|
1
|
Список
|
(Car (car *))
|
|
CADAR
|
SUBR
|
1
|
Список
|
(Car (Cdr (car *)))
|
|
CADDDR
|
SUBR
|
1
|
Список
|
(Car (Cdr (Cdr (Cdr *))))
|
|
CADDR
|
SUBR
|
1
|
Список
|
(Car (Cdr (Cdr *)))
|
|
CADR
|
SUBR
|
1
|
Список
|
(Car (Cdr *))
|
|
CAR
|
SUBR
|
1
|
Список
|
Вычисление головы списка
|
|
CDAR
|
SUBR
|
1
|
Список
|
(Cdr (Car *))
|
|
CDDDR
|
SUBR
|
1
|
Список
|
(Cdr (Cdr (Cdr *)))
|
|
CDDR
|
SUBR
|
1
|
Список
|
(Cdr (Cdr *))
|
|
CDR
|
SUBR
|
1
|
Список
|
Вычисление хвоста списка
|
|
COND
|
FSUBR
|
переменное
|
-
|
Обеспечивает вычисление условных выражений
|
|
CONS
|
SUBR
|
2
|
ANY
|
Объединяет свои аргументы в пару
|
|
CONTEXT * (13)
|
SUBR
|
1
|
ANY
|
Показвает лексический контекст функции или
лямбда-выражения. При вызове без параметров показывает текущий контекст.
|
|
CSETQ
|
FSUBR
|
2
|
1-Атом, 2-ANY
|
Создает константу
|
|
DEFDYN * (13)
|
FSUBR
|
1
|
АТОМ
|
Создает динамическую переменную (не присваивая ей значения)
|
|
DEFGLOB * (13)
|
FSUBR
|
2
|
1 - АТОМ; 2 - ANY
|
Создает глобальную переменную
|
|
DEFMACRO *
|
FSUBR
|
3
|
1-Атом, 2,3-Списки
|
Создает функцию типа MACRO (упрощенная форма SMACRO)
|
|
DEFUN *
|
FSUBR
|
3
|
1-Атом, 2,3-Списки
|
Создает функцию типа EXPR (упрощенная форма SEXPR)
|
|
DEFUNF *
|
FSUBR
|
3
|
1-Атом, 2,3-Списки
|
Создает функцию типа FEXPR (упрощенная форма SFEXPR)
|
|
DEFVAR * (13)
|
FSUBR
|
2
|
1-Атом, 2 - ANY
|
Создает динамическую переменную (с возможным присвоением значения)
|
|
DIFFERENCE (-)
|
SUBR
|
переменное >= 2
|
FIXED, FLOAT
|
Вычисляет разность первого и всех остальных аргументов
|
|
DIVIDE (/) *
|
SUBR
|
2
|
FIXED/FLOAT
|
Вычисляет частное первого и второго аргументов
|
|
DO/DO* * (13)
|
FSUBR
|
>= 2
|
Списки
|
Общий оператор цикла по группе переменных.
|
|
DOLIST * (13)
|
FSUBR
|
>= 2
|
Списки
|
Цикл по заданному списку.
|
|
DOTIMES * (13)
|
FSUBR
|
2
|
Списки
|
Цикл заданное число раз.
|
|
DOTPRINT *
|
SUBR
|
1
|
ANY
|
Печатает значение своего аргумента в точечной записи.
|
|
EQ
|
SUBR
|
2
|
ANY
|
Проверяет идентичность атомов, заданных первым и вторым аргументами.
|
|
EQL *
|
SUBR
|
2
|
ANY
|
Проверяет идентичность объектов, заданных значениями первого
и второго аргумента.
|
|
EVAL
|
SUBR
|
1
|
ANY
|
Вычисляет S-выражение
|
|
ERRORMESSAGE *
|
SUBR
|
-
|
-
|
Возвращает сообщение об ошибке в виде строки
|
|
EXPLODE *
|
SUBR
|
1
|
ATOM
|
"Взрывает" атом, разбивая имя атома на отдельные символы
|
|
EXPT
|
SUBR
|
2
|
FIXED, FLOAT
|
Вычисляет степень
|
|
FIX
|
SUBR
|
1
|
FIXED, FLOAT
|
Если значение аргумента имеет тип
FLOAT, функция возвращает значение аргумента, округленное до ближайшего
целого. Тип результата - FLOAT
|
|
FIXEDP
|
SUBR
|
1
|
ANY
|
Если значение аргумента имеет тип
FIXED, функция возвращает T; в противном случае возвращается Nil.
|
|
FIX2BIT *
|
SUBR
|
1
|
FIXED
|
Переводит целое FIXED в соответствующую
строку битов
|
|
FIX2FLO *
|
SUBR
|
1
|
FIXED
|
Переводит целое FIXED
в тип FLOAT.
|
|
FLO2FIX *
|
SUBR
|
1
|
FLOAT
|
Переводит число FLOAT
в тип FIXED.
|
|
FLO2STR *
|
SUBR
|
1
|
FLOAT
|
Переводит число FLOAT
в строку.
|
|
FLOATP *
|
SUBR
|
1
|
ANY
|
Если значение аргумента имеет тип
FLOAT, функция возвращает T; в противном случае возвращается Nil.
|
|
FORMAT *
|
SUBR
|
2
|
1-й - FIXED или FLOAT, 2-й - STRING
|
Превращает значение первого аргумента
в строку, выполняя форматирование по строке формата (2-й аргумент).
|
|
FUNCALL *
|
SUBR
|
Переменное
|
1-й - ATOM (или лямбда-выражение);
Остальные - произвольны.
|
Применяет первый аргумент (как функцию) к
остальным элементам списка параметров. Аналогична функции APPLY, но аргументы
задаются не списком, а по отдельности.
|
|
FUNCTION
|
FSUBR
|
1
|
Атом или Список
|
Задает функциональный аргумент
|
|
GC
|
SUBR
|
0
|
-
|
Вызывает сборку мусора
|
|
GENSYM (13)
|
SUBR
|
1
|
Атом
|
Строит уникальный (еще не существующий) символ
|
|
GETD
|
FSUBR
|
1
|
Атом
|
Выдает тело функции и с именем, заданным аргументом-атомом
|
|
GETEL *
|
SUBR
|
2
|
1 - Список;
2 - FIXED
|
Возвращает элемент списка-значения первого аргумента с номером,
заданным значением второго аргумента.
|
|
GEVAL * (11)
|
SUBR
|
1
|
ANY
|
Выполняет действия, аналогичные функции EVAL,
но в глобальном контексте.
|
|
GO
|
FSUBR
|
1
|
Атом
|
Перход на атом-метку
|
|
GREATERP
|
SUBR
|
2
|
ANY
|
Предикат, проверяющий, что значение первого аргумента больше второго
|
|
GREQP
|
SUBR
|
2
|
FIXED, FLOAT
|
Предикат, проверяющий, что значение первого аргумента больше или равно значению второго
|
|
GSET * (11)
|
SUBR
|
2
|
1-й - атом; 2-й - ANY.
|
Выполняет действия, аналогичные функции SET,
но атому присваивается значение в глобальном контексте.
|
|
IF * (13)
|
FSUBR
|
3
|
Формы
|
Условный оператор If (...) then (...) else (...)
|
|
IMPLODE * (13)
|
SUBR
|
1
|
список
|
"Сжимает" одноуровневый список в атом
|
|
LABELS * (13)
|
SUBR
|
2
|
ANY
|
Создает и выполняет локальные функции
|
|
LAMBDA
|
FSUBR
|
2
|
ANY
|
Задает лямбда-выражение с предварительным
вычислением аргументов
|
|
LEFTSHIFT
|
SUBR
|
2
|
1-BITS; 2-FIXED
|
Логический левый сдвиг значения первого аргумента на значение второго
|
|
LESSP
|
SUBR
|
2
|
FIXED, FLOAT
|
Предикат, проверяющий, что значение первого аргумента меньше второго
|
|
LET/LET* * (13)
|
FSUBR
|
Переменное
|
ANY
|
Вычисление в заданном лексическом контексте
|
|
LIST
|
SUBR
|
Переменное
|
ANY
|
Строит список из значений своих аргументов
|
|
LOGAND
|
SUBR
|
Переменное
|
BITS
|
Вычисляет логическое AND значений всех аргументов
|
|
LOGOR
|
SUBR
|
Переменное
|
BITS
|
Вычисляет логическое OR значений всех аргументов
|
|
LOGXOR
|
SUBR
|
Переменное
|
BITS
|
Вычисляет логическое XOR значений всех аргументов
|
|
LOOP * (13)
|
FSUBR
|
Переменное
|
ANY
|
Бесконечный цикл
|
|
MACROEXPAND *
|
FSUBR
|
Переменное >= 1
|
1-Атом, …
|
Вычисляет макрорасширение от вызова MACRO с именем, заданным 1-м аргументом, и списком параметров, заданным остальными аргументами
|
|
MAX
|
SUBR
|
Переменное
|
FIXED, FLOAT
|
Вычисляет максимум своих аргументов
|
|
MIN
|
SUBR
|
Переменное
|
FIXED, FLOAT
|
Вычисляет минимум своих аргументов
|
|
MINUS
|
SUBR
|
1
|
FIXED, FLOAT
|
Меняет знак значения своего аргумента
|
|
MINUSP
|
SUBR
|
1
|
FIXED, FLOAT
|
Проверяет, что значение аргумента отрицательно
|
|
NLAMBDA * (13)
|
FSUBR
|
2
|
Списки
|
Задает лямбда-выражение без предварительного
вычисления аргументов
|
|
NOT(NULL)
|
SUBR
|
1
|
ANY
|
Проверяет, что аргумент является пустым списком
|
|
NUMBERP
|
SUBR
|
1
|
FIXED, FLOAT
|
Проверяет, является ли значение аргумента числом
|
|
ONEP
|
SUBR
|
1
|
ANY
|
Проверяет является ли значение аргумента единицей
|
|
OR
|
FSUBR
|
переменное
|
ANY
|
Вычисляет логическое OR значений всех аргументов.
Если значение аргумента отлично от Nil, оно считается равным T.
|
|
PARSE
*
|
SUBR
|
1
|
STRING
|
Выполняет разбор алгебраического выражения на лексемы (переменные,
константы, знаки операций, скобки). Результат представляется в виде
списка.
|
|
PLUS (+)
|
SUBR
|
переменное >= 2
|
FIXED, FLOAT
|
Вычисляет сумму всех аргументов
|
|
PRINT/PRINTLINE *
|
SUBR
|
1
|
ANY
|
Печатает значение своего аргумента
|
|
PRINTS/PRINTSLINE
*
|
SUBR
|
1
|
ANY
|
Печатает значение своего аргумента,
но не заключает строки в объемлющие кавычки.
|
|
PROG
|
FSUBR
|
переменное
|
ANY
|
Задает PROG-конструкцию
|
|
PROG1/PROG2/PROGN * (13)
|
FSUBR
|
переменное
|
ANY
|
Организация программного блока
|
|
PROPLIST
|
SUBR
|
1
|
АТОМ
|
Возвращает список свойств атома-аргумента
|
|
PUTD
*
|
FSUBR
|
1
|
Список
|
Устанавливает у функции с именем, заданным значением 1-го аргумента новое определяюще выражение, заданное вторым аргументом. Тип функции (EXPR, FEXPR или MACRO) не меняется.
|
|
PUTEL
*
|
SUBR
|
3
|
1 - Список;
2 - Атом;
3 - Any.
|
Возвращает список, заданный значением первого аргумента, у которого элемент, с номером,
заданным значением второго аргумента, установлен равным значению третьего аргумента.
|
|
QUOTE
|
FSUBR
|
1
|
ANY
|
Блокирует вычисление аргумента
|
|
QUOTIENT (\)
|
SUBR
|
2
|
FIXED
|
Вычисляет целочисленное частное первого и второго аргументов
|
|
REMAINDER (%)
|
SUBR
|
2
|
FIXED
|
Вычисляет остаток от деления первого и второго аргументов
|
|
RETURN
|
SUBR
|
1
|
ANY
|
Завершает выполнение PROG-конструкции с возвратом значения 1-го аргумента
|
|
RIGHTSHIFT
*
|
SUBR
|
1
|
ANY
|
Логический правый сдвиг первого аргумента на значение второго
|
|
RPLACA
|
SUBR
|
2
|
1-Спиок, 2-ANY
|
Устанавливает значение a-указателя, записав в него значение 2-го аргумента
|
|
RPLACD
|
SUBR
|
2
|
1-Спиок, 2-ANY
|
Устанавливает значение d-указателя, записав в него значение 2-го аргумента
|
|
SET
|
SUBR
|
2
|
1-ATOM, 2-ANY
|
То же самое, что SETQ, но 1-й аргумент вычисляется
|
|
SETQ
|
FSUBR
|
2
|
1-ATOM, 2-ANY
|
Присваивает значению атома, заданному 1-м аргументом, значиения, заданному значением 2-го. 1-й агрумент не вычисляется.
|
|
SEXPR
|
FSUBR
|
2
|
1-АТОМ, 2-Список
|
Определяет функцию типа EXPR с определяющим выражением, заданным 2-м аргументом (которым должно быть лямбда-выражение)
|
|
SFEXPR
|
FSUBR
|
2
|
1-АТОМ, 2-Список
|
Определяет функцию типа FEXPR с определяющим выражением, заданным 2-м аргументом (которым должно быть лямбда-выражение)
|
|
SMACRO *
|
FSUBR
|
2
|
1-АТОМ, 2-Список
|
Определяет функцию типа MACRO с определяющим выражением, заданным 2-м аргументом (которым должно быть лямбда-выражение)
|
|
SPECIALP * (13)
|
FSUBR
|
1
|
АТОМ
|
Проверяет, является ли аргумент динамической
переменной
|
|
SPROPL
|
SUBR
|
2
|
1-Атом, 2-Список
|
Устанавливает у атома, заданного значением 1-го аргумента, новый список свойств, заданным значением 2-го аргумента
|
|
STRINGP *
|
SUBR
|
1
|
ANY
|
Если значенение аргумента имеет тип STRING, возвращается T, в противном
случае - Nil
|
|
STR2FIX *
|
SUBR
|
1
|
STRING
|
Превращает значение аргумента в число типа FIXED
|
|
STR2FLO *
|
SUBR
|
1
|
STRING
|
Превращает значение аргумента в число типа FLOAT
|
|
SUB1
|
SUBR
|
1
|
FIXED, FLOAT
|
Отнимает от значения аргумента единицу
|
|
SWAPEL *
|
SUBR
|
3
|
LIST, FIXED, FIXED
|
Меняет местами элементы списка,
заданного значением первого аргумнта. Номера обмениваемых элементов
задаются значением второго и третьего аргументов.
|
|
TERPRI
|
SUBR
|
0
|
-
|
Пропускает строку в области вывода
|
|
TIMES (*)
|
SUBR
|
переменное >= 2
|
FIXED, FLOAT
|
Вычисляет произведение всех аргументов
|
|
TRY *
|
SUBR
|
3
|
1-S-выражение;
2-Атом "EXCEPT";
3-S-выражение;
|
Вычисление S-выражения с перехватом ошибки.
|
|
WHEN * (13)
|
FSUBR
|
переменное
|
формы
|
Вычислить, если истино
|
|
UNLESS * (13)
|
FSUBR
|
переменное
|
формы
|
Вычислить, если ложно
|
|
UNSET *
|
SUBR
|
1
|
Атом
|
Уничтожает переменную, заданную значением аргумента.
|
|
ZEROP
|
SUBR
|
1
|
ANY
|
Проверяет является ли значение аргумента нулем
|
|
|
|
|
|
|
|
Функция ABS принимает единственный аргумент числового типа (FIXED
или FLOAT). Она вычисляет абсолютною величину аргумента. Тип результата
совпадает с типом аргумента. Примеры:
(ABS -7.0)
==> 7.0
(PROPLIST (ABS -7.0))
==> (FLOAT)
(ABS 54)
==> 54
(PROPLIST (ABS 54))
==> (FIXED)
|
|
|
|
|
|
|
|
|
Функция ADD1 принимает единственный аргумент числового типа (FIXED
или FLOAT). Она прибавляет единицу к значению аргумента. Тип результата
совпадает с типом аргумента. Примеры:
(ADD1 -7.0)
==> -6.0
(PROPLIST (ADD1 -7.0))
==> (FLOAT)
(ADD1 54)
==> 55
(PROPLIST (ADD1 54))
==> (FIXED)
|
|
|
|
|
|
|
|
|
Функция AND принимает произвольное число аргументов. Первый же аргумент, имеющий значений NIL
вызывает прекращение вычисление, а функция возвращает значение NIL. Если значение всех аргументов
функции отлично от NIL, то функция принимает значение, равное значению последнего аргумента.
Примеры:
(AND 1 2 3)
==> 3
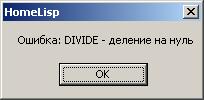
(AND 1 (CDR '(1)) (/ 3 0))
==> NIL
|
Обратите внимание, во втором примере третий аргумент (/ 3 0) даже не вычислялся (в противном случае
возникла бы ошибка "деление на нуль"). Это происходит вследствие того, что AND - функция
класса FSUBR. Ее аргументы не вычисляются (точнее вычисление происходит не перед,
а после вызова в теле функции от первого к последнему). Второй аргумент после вычисления
дает Nil, и вычисление прекращается. Если во втором аргументе заменить CDR
на CAR, то возникнет ошибка "деление на нуль".
|
|
|
|
|
|
|
|
|
|
Функция APPLY принимает ровно 2 аргумента. Первым
аргументом может быть атом или лямбда-выражение. Вторым
аргументом должен быть список. Функция APPLY применяет
первый аргумент к элементам списка, которые составляют второй
аргумент.
Так, вызов:
(Apply fn
Список)
полностью эквивалентен
вызову:
(fn 'x1 'x2 ...
'xn)
При этом предполагается,
что:
Список = (x1 x2 ...
xn)
Примеры:
(apply 'plus '(1 6))
==> 7
(apply 'cons '(язык (программирования)))
==> (язык программирования)
(setq f 'Plus)
==> PLUS
(apply f '(7 8))
==> 15
(apply 'apply '(plus (5 7)))
==> 12
(apply '(lambda (x y) (* x y)) '(9 8))
==> 72
(apply 'plus 1 6)
Третий аргумент APPLY - не список
==> ERRSTATE
|
В последнем примере допущена ошибка - аргументы функции
PLUS, которая вызывается через APPLY, не
сгруппированы в список. Функция APPLY отсутствует в
реализации Лаврова и Силагадзе, она (как и описанная ниже
функция FUNCALL) введена в
HomeLisp для совместимости с современнымы версиями
Лиспа.
|
|
|
|
|
|
|
|
Функция ATOM принимает единственный аргумент. Она проверяет, является ли аргумент атомом (в этом случае
возвращается значение T. В противном случае возвращается значение Nil.
Примеры:
(ATOM 1)
==> T
(ATOM '(1 2 3))
==> NIL
(ATOM (+ 2 3))
==> T
|
Третий пример может вызвать недоумение: ведь аргументом здесь является список
(+ 2 3), а не атом! Тем не менее функция возвращает T. Ведь функция ATOM
принадлежит классу SUBR; ее аргументы вычисляются. Это означает, что перед тем,
как вычислять выражение (ATOM ...) будет вычислено выражение (+ 2 3). Значение этого
выражения - атом 5. После вычисления (+ 2 3) будет, таким образом, вычисляться
выражение (ATOM 5), значение которого, естественно равно T. Новичку полезно
вычислить выражение (ATOM (+ 2 3)), включив режим дампирования. По дампу будет
видно, как происходит вычисление выражения:
.EVAL вход: (ATOM (PLUS 2 3))
..CAR вход: A= (ATOM (PLUS 2 3))
..CAR выход: Рез= ATOM
..CDR вход: A= (ATOM (PLUS 2 3))
..CDR выход: Рез= ((PLUS 2 3))
..APPLY вход: A1= ATOM A2= ((PLUS 2 3))
...EVFUN вход: A1= ATOM A2= ((PLUS 2 3))
....LIST вход: A= ((PLUS 2 3))
.....CAR вход: A= ((PLUS 2 3))
.....CAR выход: Рез= (PLUS 2 3)
.....EVAL вход: (PLUS 2 3)
......CAR вход: A= (PLUS 2 3)
......CAR выход: Рез= PLUS
......CDR вход: A= (PLUS 2 3)
......CDR выход: Рез= (2 3)
......APPLY вход: A1= PLUS A2= (2 3)
.......EVFUN вход: A1= PLUS A2= (2 3)
........LIST вход: A= (2 3)
.........CAR вход: A= (2 3)
.........CAR выход: Рез= 2
.........EVAL вход: 2
..........EVATOM вход: 2
..........EVATOM выход: 2
.........EVAL выход: 2
.........CDR вход: A= (2 3)
.........CDR выход: Рез= (3)
.........CAR вход: A= (3)
.........CAR выход: Рез= 3
.........EVAL вход: 3
..........EVATOM вход: 3
..........EVATOM выход: 3
.........EVAL выход: 3
.........CDR вход: A= (3)
.........CDR выход: Рез= NIL
........LIST выход: Рез= (2 3)
........PLUS вход: A= (2 3)
.........CAR вход: A= (2 3)
.........CAR выход: Рез= 2
........PLUS Пром. Рез=2
.........CDR вход: A= (2 3)
.........CDR выход: Рез= (3)
.........CAR вход: A= (3)
.........CAR выход: Рез= 3
........PLUS Пром. Рез=5
.........CDR вход: A= (3)
.........CDR выход: Рез= NIL
........PLUS выход: Рез= 5
.......EVFUN выход: 5
......APPLY выход: 5
.....EVAL выход: 5
.....CDR вход: A= ((PLUS 2 3))
.....CDR выход: Рез= NIL
....LIST выход: Рез= (5)
....CAR вход: A= (5)
....CAR выход: Рез= 5
....ATOM вход: A= 5
....ATOM выход: Рез= T
...EVFUN выход: T
..APPLY выход: T
.EVAL выход: T
|
|
|
|
|
|
|
|
|
Функция BACKQUOTE (реализованная только в 13-й
редакции ядра)
делает почти то же самое, что и классическая функция
QUOTE - возвращает свой аргумент без вычисления. Однако имеются два исключения:
 Если перед атомом или списком, входящим в состав аргумента
стоит запятая, то этот атом или список вычисляется и результат вставляется в
результирующее выражение. Причем, если результатом вычисления оказывается список,
то этот список оказывается на более глубоком уровне вложенности. Если перед атомом или списком, входящим в состав аргумента
стоит запятая, то этот атом или список вычисляется и результат вставляется в
результирующее выражение. Причем, если результатом вычисления оказывается список,
то этот список оказывается на более глубоком уровне вложенности.
Если перед атомом или списком, входящим в состав аргумента
стоит ,@, то элемент также вычисляется, но "присоединяется" к результату на том
же уровне вложенности.
Вызов функции BACKQUOTE можно записывать с помощью символа "`" обратный апростроф
(по аналогии с записью QUOTE с помощью обычного апострофа.
Вот поясняющие примеры:
(setq p '(1 2 3))
==> (1 2 3)
Создана глобальная переменная p
`(1 2 ,p 3 4)
==> (1 2 (1 2 3) 3 4)
`(1 2 ,p 3 4 ,@p)
==> (1 2 (1 2 3) 3 4 1 2 3)
`(111 222 ,(fact 10) 333)
==> (111 222 3628800 333)
`(111 222 ,@(fact 10) 333)
BackQoute: Конструкция ",@" стоит перед атомом
==> ERRSTATE
`(111 222 ,@(mklist1 10) 333)
==> (111 222 10 9 8 7 6 5 4 3 2 1 333)
|
Здесь создана глобальная переменная p и ей присвоено значение (1 2 3).
При вычислении `(1 2 ,p 3 4) конструкция ,p заменяется на список
(1 2 3), причем этот список оказывается на более глубоком уровне вложенности
(т.н. включающая обратная блокировка).
Далее показана разница в поведении ,ANY и ,@ANY: конструкция ,p
превращается во вложенный список, тогда как список, получаемый при обработке ,@p
присоединяется к текущему на том же уровне (т.н. присоединяющая обратная блокировка).
В следующем примере ,(fact 10) заменяется атомом 3628800. А вот попытка
использовать конструкцию ,@(fact 10) вызывает ошибку - присоединяющая обратная блокировка
может применяться только к спискам. Следующий пример показывает, что список присоединяется
успешно.
Наиболее частое применение обратная блокировка находит при программировании macro.
Вот пример, иллюстрирующий применение обратной блокировки в макро. Построим макрос,
который по заданному списку строит новый "удвоенный" список (каждый элемент верхнего
уровня исходного списка в результирующем списке заменяется двумя такими же элементами).
Вот как выглядит такой макрос c использованием обратной блокировки:
(defmacro double-list (a-list)
`(let ((ret nil))
(dolist (x ,a-list)
(setq ret (append ret (list x x))))
ret)
)
==> double-list
(double-list '(a b c (d e f)))
==> (a a b b c c (d e f) (d e f))
(macroexpand double-list '(1 2 3))
==> (LET ((ret NIL))
(DOLIST (x (QUOTE (1 2 3)))
(SETQ ret (append ret (LIST x x)))) ret)
|
В сущности, макро строит предложение LET, в единственное место которого
нужно подставить значение параметра (это место выделено красным).
С использованием обратной блокировки задача решается очень наглядно и изящно:
мы просто пишем нужное выражение, предварив его обратным апострофом,
а в нужных местах перед элементами, которые требутся вычислить ставим
запятую или пару ",@". Хорошо видно, что тело макро почти не отличается от
результата макрорасширения!
Все обстояло бы совсем по-другому, если бы не было возможности использовать
обратную блокировку. Ниже приводится макрос, решающий прежнюю задачу, но
не использующий функцию BACKQUOTE:
(defmacro dbl-lst (a-list)
(list 'let (list (list 'ret nil))
(list 'dolist (list 'x a-list)
(list 'setq 'ret
(list 'append 'ret (list 'list 'x 'x))))
'ret
)
)
==> dbl-lst
(dbl-lst '(a b c (d e f)))
==> (a a b b c c (d e f) (d e f))
(macroexpand dbl-lst '(1 2 3))
==> (LET ((ret NIL))
(DOLIST (x (QUOTE (1 2 3)))
(SETQ ret (append ret (LIST x x)))) ret)
|
Как можно убедиться, тело макроса dbl-lst воспринимается значительно труднее,
чем тело макроса double-list. Связь тела макроса с результатом макрорасширения
в данном случае совсем не очевидна (хотя результат макрорасширения макросов
dbl-lst и double-list одинаков.
|
|
|
|
|
|
|
|
Функция-предикат BITSP принимает единственный аргумент. Если значением аргумента является битовое
значение, функция возвращает T. В противном случае функция возвращает Nil Примеры:
(BITSP '(1 2 3))
==> Nil
(BITSP &H55)
==> T
(BITSP (FIX2BIT 678))
==> T
|
В последнем примере сначала вычисляется выражение (FIX2BIT 678), имеющее значение &H2A6. Это значение
имеет битовый тип, поэтому окончательный результат равен T.
|
|
|
|
|
|
|
|
Функция BIT2FIX, отсутствующая у Лаврова и Силагадзе, принимает единственный аргумент типа BITS.
функция возвращает значение аргумента, преобразованное к типу FIXED. При этом, если старший бит аргумента
установлен, то результатом будет отрицательное число (в этом случае предполагается, что отрицательные числа хранятся
в дополнительном коде). Если аргумент функции BIT2FIX имеет тип, отличный от BITS, возникает ошибка.
Примеры:
(BIT2FIX &H55)
==> 85
(BIT2FIX &HFFFFFFF7)
==> -9
(BIT2FIX 678)
==> Аргумент BIT2FIX должен иметь тип BITS
|
|
|
|
|
|
|
|
|
Функция CAR принимает единственный аргумент - список или точечную пару. Она возвращает голову списка
(первый элемент списка на верхнем уровне). Если аргумент - не список и не пара (атом), то возникает
ошибка. Примеры:
(CAR '(1 2 3))
==> 1
(CAR '((1 2) 3))
==> (1 2)
(CAR '(a . b))
==> a
(CAR 'a)
==> Аргумент CAR - атом (a)
|
Во втором примере результат получается (1 2), а не 1, как могло бы показаться
при поверхностном взгляде. Аргумент CAR это список из ДВУХ элементов:
списка (1 2) и атома 3. Функция CAR возвращает ПЕРВЫЙ элемент -
список (1 2).
|
|
|
|
|
|
|
|
Функция CDR принимает единственный аргумент - список или точечную пару. Она возвращает хвост списка
- список без первого элемента. Если аргумент не список и не пара (атом), то возникает
ошибка. Примеры:
(CDR '(1 2 3))
==> (2 3)
(CDR '((1 2) 3))
==> (3)
(CDR '(a . b))
==> b
(CDR 'a)
==> Аргумент CDR - атом (a)
(CDR '(3))
==> Nil
|
Во втором примере результат получается (3), а не 3, как могло бы показаться
новичку. Аргумент CDR это список из ДВУХ элементов:
списка (1 2) и атома 3. Функция CDR возвращает список (3) -
исходный список без первого элемента. Ситуацию может прояснить то обстоятельство, что в терминах
точечных пар исходный список записывается так: ((1 . (2 . Nil)) . (3 . Nil));
применяя функцию CDR к этой конструкции, мы получим (3 . Nil), а это есть
в точности (3). Вполне очевиден результат и последнего примера.
|
|
|
|
|
|
|
|
Поскольку функции CAR и CDR применяются для выделения частей списков (разбора
списков на составные части), в язык встроено несколько комбинаций CAR и CDR:
(CAAR ... ) это (CAR (CAR ...))
(CADAR ...) это (CAR (CDR (CAR ...)))
(CADDR ...) это (CAR (CDR (CDR ...)))
(CADDDR ...) это (CAR (CDR (CDR (CDR ...))))
(CADR ...) это (CAR (CDR ...))
(CDAR ...) это (CDR (CAR ...))
(CDDR ...) это (CDR (CDR ...))
(CDDDR ...) это (CDR (CDR (CDR ...)))
|
Естественно, что эти функции можно вычислить не для всякого значения аргумента. Так,
при попытке вычислить (CAAR '(1 2)) возникнет ошибка, поскольку (CAR '(1 2))
равен 1, а попытка вычислить (CAR 1) приведет к ошибке, т.к. здесь аргумент
CAR - не список и не точечная пара, а атом.
|
|
|
|
|
|
|
|
Функция COND обеспечивает вычисление условных выражений. Общий вид функции COND
таков:
(COND
((Условие-1) Результат-1)
((Условие-2) Результат-2)
...
((Условие-n) Результат-n)
(T Результат)
)
|
Вычисление функции COND происходит следующим образом: вычисляется (Условие-1); если
получается результат, отличный от Nil, то в качестве результата выдается значение выражения Результат-1.
Если (Условие-1) ложно (= Nil), то вычисляется (Условие-2). Если снова получается
результат, отличный от Nil, то в качестве результата выдается значение выражения Результат-2 и т.д. Если в
конструкции COND присутствует часть (T Результат) и ни одно из
условий не оказалось истиным, то в качестве результата выдается значение выражения Результат.
В случае отсутствия части (T Результат) при ложности всех условий,
результатом COND будет Nil. Легко видеть, что функция COND похожа
на оператор множественного выбора SELECT языка Visual Basic, а конструкция
(T Результат) играет роль CASE ELSE.
Вот пример вызова функции COND.
Пусть были введены команды (SETQ x 6) , (SETQ y 7) и (SETQ z 1) . Другими словами,
переменная x имеет значение 6, переменная y - значение 7, а
переменная z имеет значение 1. Тогда:
(COND
((EQ x y) "Равно")
(T "Не равно")
)
==> "Не равно"
(COND
((EQ (+ x z) y) "Равно")
(T "Не равно")
)
==> "Равно"
|
|
|
|
|
|
|
|
|
Функция CONS принимает два аргумента и объединяет их в точечную пару. Таким образом,
если оба аргумента CONS - атомы, отличные от Nil, то функция вернет точечную
пару, составленную из атомов. Если первый аргумент - атом, а второй - список, то результатом
CONS будет новый список, получающийся добавлением первого аргумента к началу списка из
второго аргумента. В частности, если первый аргумент - атом, а второй аргумент - Nil,
то в результате получится одноэлементный список, состоящий из первого аргумента. Это происходит
потому, что в Лиспе Nil считается пустым списком. А если оба аргумента CONS
- списки, то в результате получится новый двухуровневый список, голова которого есть
значение первого аргумента, а хвост - значение второго аргумента.
Все это иллюстрируется следующими примерами:
(CONS 'A 'B)
==> A . B
(CONS 'A '(1 2 3))
==> (A 1 2 3)
(CONS 'A Nil)
==> (A)
(CONS '(A B C) '(1 2 3))
==> ((A B C) 1 2 3)
|
|
|
|
|
|
|
|
|
Функция CONTEXT (реализованная только в 13-й версии ядра) принимает принимает один необязательный аргумент - атом. Если этот атом
есть имя функции типа EXPR/FEXPR/MACRO и функция определена с сохранением лексического
окружения (создано замыкание), то функция CONTEXT вернет лексическое окружение
в виде списка пар ((Переменная Значение) (Переменная Значение) ... ).
Аналогичный результат будет получен в случае, когда значением аргумента CONTEXT
является замыкание, созданное на основе лямбда-выражения или FUNCTION. В остальных
случаях функция CONTEXT возвращает Nil.
Если функция CONTEXT вызвана без параметров, то она возвращает список из двух элементов -
первый элемент является списком активных лексических переменных в точке вызова,
а второй элемент - списком активных динамических и глобальных переменных. Естественно,
что при вызове функции CONTEXT без параметров на верхнем уровне список
лексических переменных будет пуст. Но при вызове внутри выполняющейся функции можно
увидеть активные лексические переменные.
Рассмотрим некоторые примеры:
(context)
==> (Nil Nil)
(setq p '(1 2 3))
==> (1 2 3)
Создана глобальная переменная p
(context)
==> (NIL ((p (1 2 3))))
(defun fff (x y) (printline (context)) (list x y))
==> fff
(fff 666 777)
(((y 777) (x 666)) ((p (1 2 3))))
==> (666 777)
(defun ggg (x y &aux z) (printline (context)) (list x y))
==> ggg
(ggg 666 777)
(((z NIL) (y 777) (x 666)) ((p (1 2 3))))
==> (666 777)
(prog (x y)
(setq x 111)
(setq y 222)
(printline (context))
(return (+ x y))
)
(((y 222) (x 111)) ((p (1 2 3))))
==> 333
|
Выше показано, что вызов функции CONTEXT без параметров на верхнем
уровне при отсутствии глобальных и динамических переменных возвращает "пустой"
контекст - (Nil Nil).
После создания глобальной переменной p эта переменная попадает в глобальный
контекст.
Далее создается простая функция двух переменных, в тело которой встроен
вызов функции CONTEXT. Кстати, пусть читатель обратит внимание на то,
что значение контекста печатается. Если опустить печать, функция просто
вернет список значений своих аргументов, а контекст увидеть не удастся.
Видно, что в теле функции появляется лексический контекст - параметрам присваиваются
соответствующие значения.
В следующем примере показана функция ggg
с дополнительным параметром. Этот параметр тоже попадает в лексический контекст.
Наконец, последний пример показывает, что в лексический контекст попадают и PROG-переменные.
Функция CONTEXT позволяет увидеть лексические переменные замыкания. Ниже показан
пример, где с помощью замыкания создается простейший генератор. Функция CONTEXT
позволяет увидеть внутреннее значение счетчика:
(setq z 111)
==> 111
Создана глобальная переменная z
(let ((c 0)) (defun next-c nil (setq c (add1 c))))
==> next-c
(next-c)
==> 1
(next-c)
==> 2
(context 'next-c)
==> ((c 2))
|
Видно, что когда функция CONTEXT отображает контекст замыкания, то отображается
только лексический контекст (глобальная переменная z не отображается).
В следующем примере создается замыкание на основе лямбда-выражения. В контекст
этого замыкания входят две переменные (a и b). Их значения показывает
функция CONTEXT. Впрочем, значения лексических замыкания можно увидеть,
просто напечатав значение переменной, которой присвоено замыкание.
(let ((a 111) (b 222)) (setq f (lambda (x) (list a b x))))
==> (CLOSURE (x) ((LIST a b x)) ((b 222) (a 111)))
Создана глобальная переменная f
f
==> (CLOSURE (x) ((LIST a b x)) ((b 222) (a 111)))
(context f)
==> ((b 222) (a 111))
(funcall f 333)
==> (111 222 333)
|
Пусть читатель обратит внимание на то, что в приведенном выше примере при
вызове CONTEXT аргумент не квотируется.
Следующий далее пример в общем аналогичен предыдущему (только замыкание здесь
создается с помощью конструкции FUNCTION):
(defun g (x) (+ a b x))
==> g
(g 1)
Assoc: Символ a не имеет значения (не связан).
==> ERRSTATE
(setq ff (let ((a 111) (b 222)) (function g)))
==> (CLOSURE g ((a 111) (b 222)))
Создана глобальная переменная ff
(funcall ff 333)
==> 666
(context ff)
==> ((a 111) (b 222))
|
|
|
|
|
|
|
|
|
Функция CSETQ принимает два аргумента; первый аргумент
должен быть атомом (он не вычисляется), а второй - произвольным
S-выражением. Функция превращает атом (первый аргумент) в
константу; при этом константа наследует тип вычисленного
S-выражения. Значение константы
впоследствии не может быть изменено (в отличие от
переменной, создаваемой фунциями SET/SETQ). Если
атом-аргумент является переменной, возникает ошибка. При
попытке изменить значение константы повторным вызовом
CSETQ возникает ошибка c диагностикой "Csetq -
попытка изменить значение константы". То же будет иметь
место при попытке изменить значение встроенной константы
( Nil, T, ERRSTATE, _Pi, _E, _Ver ). Так же закончится и
попытка присвоить одному числу значение другого. Если же
попытаться создать переменную, одноименную с константой с
помощью функций SETQ/SET, то будет выдана диагностика
"Попытка превратить константу ... в переменную". Ниже
приводятся примеры на эту тему.
(CSETQ K 12)
==> 12
(CSETQ K -5)
==> Csetq - попытка изменить значение константы
(SETQ kk 3)
==> 3
(CSETQ kk 8)
==> Csetq - попытка превратить переменную в константу
(SETQ _Pi 5)
==> Попытка превратить константу _Pi в переменную
(CSETQ 1 2)
==> Csetq - попытка изменить значение константы
(CSETQ "a" "b")
==> Csetq - попытка изменить значение константы
(CSETQ Nil T)
==> Csetq - попытка изменить значение константы
|
HomeLisp располагает встроенным механизмом, позволяющим
защитить значение константы (произвольное S-выражение) от модификации.
Казалось бы, что если значением константы является сложное S-выражение,
то его части могут быть изменены например
вызовом функций RPLACA/RPLACD. В действительности же такая попытка
завершится ошибкой:
(csetq AA '(a b c))
==> AA
AA
==> (a b c)
(rplaca AA 'd)
RPLACA: попытка модификации защищенной структуры
==> ERRSTATE
AA
==> (a b c)
(setq BB '(a b c))
==> (a b c)
(rplaca BB 'd)
==> (d b c)
BB
==> (d b c)
|
Из приведенного примера видно, что значения переменной может
модифицироваться с помощью "разрушающих" функций rplaca/rplacd,
а попытка модифицировать значение константы вызывает ошибку.
Замечание.
В 13-й редакции
ядра константа не может использоваться в качестве формального параметра функций. При
попытке такого использования возникает ошибка:
(csetq n 'a)
==> n
(defun f (x n) (cons x (cons n nil)))
SEXPR: Неверна структура списка параметров (-13)
==> ERRSTATE
(defun f (t x) (cons t (cons x nil)))
SEXPR: Неверна структура списка параметров (-13)
==> ERRSTATE
|
Здесь видно, что невозможно определить функцию с формальным параметром-константой,
неважно, встроенной (t) или определенной пользователем (n).
Приведенные далее сведения этого раздела относятся к 11-й
редакции ядра HomeLisp.
Как отмечают Лавров и Силагадзе, связь, накладываемая на
именования констант функцией CSETQ сильнее связи,
накладываемой при именовании переменных лямбда-выражением.
Константы нельзя (точнее - бесполезно!) использовать в качестве
связанных переменных. Вот пример на эту тему из книги Лаврова и
Силагадзе:
(csetq n 'a)
==> a
(defun f (t n) (cons t (cons n nil)))
==> f
(f 'b 'c)
==> (t a)
|
Казалось бы, вызов функции f должен дать список (b
c), однако, поскольку в списке параметров функции стоят две
константы - встроенная T и созданная пользователем
N, связь с фактическими параметрами не срабатывает.
Поучительно посмотреть, как отажается в дампе процесс
вычисления:
.EVAL вход: (f (QUOTE b)(QUOTE c))
..APPLY вход: A1= f A2= ((QUOTE b)(QUOTE c))
...EVFUN вход: A1= f A2= ((QUOTE b)(QUOTE c))
....LIST вход: A= ((QUOTE b)(QUOTE c))
.....EVAL вход: (QUOTE b)
......APPLY вход: A1= QUOTE A2= (b)
.......EVFUN вход: A1= QUOTE A2= (b)
.......EVFUN выход: b
......APPLY выход: b
.....EVAL выход: b
.....EVAL вход: (QUOTE c)
......APPLY вход: A1= QUOTE A2= (c)
.......EVFUN вход: A1= QUOTE A2= (c)
.......EVFUN выход: c
......APPLY выход: c
.....EVAL выход: c
....LIST выход: Рез= (b c)
....EVLAM вход: A1= ((T n)(CONS T (CONS n NIL))) A2= (b c)
.....PAIRLIS вход: ptrAasso=0 A1= (T n) A2= (b c)
.....
..... Ассоциативный список:
.....
..... 2 -> (n . c)
..... 1 -> (T . b)
.....
.....PAIRLIS выход: ptrAsso=2
.....EVAL вход: (CONS T (CONS n NIL))
......APPLY вход: A1= CONS A2= (T (CONS n NIL))
.......EVFUN вход: A1= CONS A2= (T (CONS n NIL))
.......
....... Ассоциативный список:
.......
....... 2 -> (n . c)
....... 1 -> (T . b)
.......
........LIST вход: A= (T (CONS n NIL))
.........EVAL вход: T
..........EVATOM вход: T
..........EVATOM выход: T
.........EVAL выход: T
.........EVAL вход: (CONS n NIL)
..........APPLY вход: A1= CONS A2= (n NIL)
...........EVFUN вход: A1= CONS A2= (n NIL)
...........
........... Ассоциативный список:
...........
........... 2 -> (n . c)
........... 1 -> (T . b)
...........
............LIST вход: A= (n NIL)
.............EVAL вход: n
..............EVATOM вход: n
..............EVATOM выход: a
.............EVAL выход: a
.............EVAL вход: NIL
..............EVATOM вход: NIL
..............EVATOM выход: NIL
.............EVAL выход: NIL
............LIST выход: Рез= (a NIL)
............CONS вход: A1= a A2= (NIL)
............CONS выход: Рез= (a)
...........EVFUN выход: (a)
..........APPLY выход: (a)
.........EVAL выход: (a)
........LIST выход: Рез= (T (a))
........CONS вход: A1= T A2= ((a))
........CONS выход: Рез= (T a)
.......EVFUN выход: (T a)
......APPLY выход: (T a)
.....EVAL выход: (T a)
....EVLAM выход: Рез= (T a)
...EVFUN выход: (T a)
..APPLY выход: (T a)
.EVAL выход: (T a)
|
Видно, что несмотря на образование в ассоциативном списке
правильных связей, при вычислении значений атомов T и
n (выделено красным) ассоциативный список просто
игнорируется. Вместе с тем, если ввести аналогичную функцию,
формальные аргументы которой не являются константами, результат
будет другой:
(defun f (x y) (cons x (cons y nil)))
==> f
(f 'b 'c)
==> (b c)
|
|
|
|
|
|
|
|
|
Функция DEFDYN реализована только в 13-й
редакции ядра. Функция (типа FSUBR) принимает один параметр параметр-атом и один необязательный - произвольное S-выражение.
Функция DEFDYN является полным синонимом функции DEFVAR.
Если задан только один параметр-атом, то функция превращает этот символ в
динамическую переменную (не присваивая нового значения и не меняя существующего).
Если указано два параметра, и символ, заданный первым параметром, еще не имел значения,
то функция превращает этот символ в динамическую переменную, со значением, равным значению второго
параметра.
Если указано два параметра, и символ, заданный первым параметром, уже имеет значение,
то функция превращает этот символ в динамическую переменную, не присваивая нового значения.
параметра.
Все сказанное иллюстрируется врезкой:
(defdyn v)
==> v
v
Assoc: Символ v не имеет значения (не связан).
==> ERRSTATE
(defdyn w 111)
==> w
w
==> 111
(defdyn w 222)
==> w
w
==> 111
|
Создана динамическая переменная v (точнее, с этого момента символ v будет задавать динамическую
переменную). Но символ v пока не получил никакого значения. Далее создается динамическая переменная
w с присвоением ей значения 111. Последующая попытка сменить значение переменной w
с помощью DEFDYN не имеет успеха.
Ниже приведен пример, показывающий разницу в поведении лексических и динамических переменных.
(defun f (x) (* x a))
==> f
(let ((a 1)) (f 5))
Внутри LET: Assoc: Символ a не имеет значения (не связан).
==> ERRSTATE
(let ((a 1)) (printline (+ a 7)) (f 5))
8
Внутри LET: Assoc: Символ a не имеет значения (не связан).
==> ERRSTATE
(defdyn 'a)
==> a
(let ((a 1)) (printline (+ a 7)) (f 5))
8
==>5
|
Переменная a (по умолчанию - лексическая) становится динамической после вызова (defdyn 'a). Теперь значение
переменной a доступно в теле функции f.
|
|
|
|
|
|
|
|
Функция DEFGLOB принадлежит к типу FSUBR и реализована только в 13-й редакции ядра HomeLisp
Функция создает глобальную переменную и присваивает ей значение Nil. Другой способ создания глобальной переменной состоит в вызове
SET/SETQ. Если переменная, заданная первым параметром SET/SETQ, не существует в текущем лексическом контексте, будет создана
глобальная переменная. Поскольку вызовы SET/SETQ на верхнем уровне выполяются в пустом лексическом контексте, то такой вызов всегда
создает или модифицирует глобальные переменные. В общем использование SET/SETQ и DEFGLOB совершенно равноправно; без
DEFGLOB можно было бы обойтись. DEFGLOB введена в HomeLisp для "синтаксической симметрии".
Рассмотрим примеры:
(defglob v)
==> v
Создана глобальная переменная v
v
==> NIL
(setq vv 777)
==> 777
Создана глобальная переменная vv
(varlist)
+------------------+---------+----------+
| Имя переменной | Тип | Значение |
+------------------+---------+----------+
|vv |Глобальн.|777 |
|v |Глобальн.|NIL |
+------------------+---------+----------+
==> T
|
Следует обратить внимание на то, что глобальная переменная может быть динамической. В этом случае ее поведение будет иметь
некоторые отличия. Вот развернутый пример на эту тему:
(setq v 111)
==> 111
Создана глобальная переменная v
(defun f (x) (* x v))
==> f
(defun g (v) (f 7))
==> g
(g 222)
==> 777
(defdyn v)
==> v
(g 222)
==> 1554
|
Создана глобальная переменная v и функция f, относительно которой переменная v свободна.
Далее создается функция g, у которой переменная v входит в список параметров. При вычислении
(g 222) переменная v является лексической и значение 222 не попадает в функцию f, -
берется глобальное значение 111 (результат = 777 = 7 * 111). Далее переменная v делается
динамической; теперь при вычислении (g 222) в функции f будет взято значение 222 (фактический
параметр при вызове g. Результат получается равным 1554 ( 222 * 7).
|
|
|
|
|
|
|
|
Функции DEFMACRO является упрощенной формой функции
SMACRO. Понятие макро в Лиспе подробно рассмотрено в
разделе, посвященном функции SMACRO.
Функцию DEFMACRO разработчик ввел в HomeLisp для совместимости с современными
версиями Лиспа.
Функция DEFMACRO принимает три параметра: имя создаваемой
функции, список ее формальных параметров и тело функции. При удачном
завершении функция возвращает атом-имя, а в системе появляется
новая макрофункция.
Рассмотрим пример создания простейшей макро-функции. Наша функция
будет брать на вход список чисел и код арифметической операции.
Она должна вычислить результат применения заданной операции к списку.
(defmacro arlist (L OP) (cons OP L))
==> arlist
(arlist (1 2 3 4 5 6) *)
==> 720
(macroexpand arlist (1 2 3 4 5 6) *)
==> (* 1 2 3 4 5 6)
(arlist (1 2 3 4 5) +)
==> 15
(macroexpand arlist (1 2 3 4 5 ) +)
==> (+ 1 2 3 4 5)
|
Макро работает очень просто: создает новый список,
в котором заданная операция является первым элементом.
Впоследствии результат макро-расширения вычисляется (и получается верный результат).
|
|
|
|
|
|
|
|
Функция DEFUN добавлена исключительно для
совместимости с более поздними версиями Лиспа. DEFUN
позволяет создавать функции типа EXPR несколько проще,
чем базовая функция SEXPR. Функция принимает три
аргумента: имя вновь создаваемой функции (атом); список
формальных параметров (список) и тело функции без атома
LAMBDA (тоже список). При успехе DEFUN возвратит
имя вновь созданной функции (первый аргумент). Создадим
функцию, вычисляющую сумму элементов списка произвольной длины,
состоящего из чисел или констант, имеющих числовое
значение. Это будет рекурсивная функция, работающая
следующим образом: если список пуст, функция должна вернуть
нуль. Если аргумент функции - атом, то функция должна вернуть
этот атом в качестве значения (предполагаем, что на вход
функции подается список из чисел). Наконец, если аргумент -
список, то функция берет значение головы списка и прибавляет к
нему значение функции, взятой от хвоста списка (стандартное
использование рекурсии). Все это выглядит так:
(defun Сумма (x)
(cond ((null x) 0)
((Atom x) x)
(T (+ (car x) (Сумма (Cdr x))))
)
)
|
Если вычислить (Сумма '(1 2 3 4)), получим результат 10 - функция работает.
|
|
|
|
|
|
|
|
Функция DEFUNF (как и функция DEFUN) добавлена для
совместимости с более поздними версиями Лиспа. DEFUNF
позволяет создавать функции типа FEXPR несколько проще,
чем базовая функция SFEXPR. Функция принимает три
аргумента: имя вновь создаваемой функции (атом); список
формальных параметров (список) и тело функции (тоже список). При успехе DEFUNF возвратит
имя вновь созданной функции (первый аргумент).
Создадим (следуя книге Лаврова и Силагадзе) функцию PAIRQ,
которая объединяет два своих аргумента в список:
(defunf pairq (x y) (cons x (cons y nil)))
==> pairq
(pairq 1 2)
==> (1 2)
(pairq (1 2) (3 4))
==> ((1 2) (3 4))
|
Видно, что функция работает. Пользоваться ею, на первый взгляд, удобно
(не нужно квотировать аргументы). Но при попытке вычислить функцию с выражениями
на месте аргументов, мы получим обескураживающий результат:
(pairq (+ 2 3) (+ 7 8))
==> ((+ 2 3) (+ 7 8))
|
Вместо списка (5 15) мы получили совсем другой результат (чего
бы не случилось, если бы функция принадлежала классу EXPR).
|
|
|
|
|
|
|
|
Функция DEFVAR, реализованная только в 13-й версии ядра, является полным синонимом функции
DEFDYN, описанной выше.
|
|
|
|
|
|
|
|
Функция DIFFERENCE вычисляет разность значений первого и всех остальных аргументов.
Аргументов может быть произвольное количество. Допустимы только значения аргументов
FIXED и FLOAT. Если все аргументы DIFFERENCE имеют тип FIXED,
то и результат будет иметь тип FIXED. Если же среди аргументов DIFFERENCE
встретился аргумент типа FLOAT, то и результат будет иметь тип FLOAT.
Для удобства записи допустимо вместо (DIFFERENCE ...) писать (- ...).
Вот примеры,иллюстрирующие сказанное:
(- 1 2 3)
==> -4
(PROPLIST (- 1 2 3))
==> (FIXED)
(DIFFERENCE 3 1.0)
==> 2.0
(PROPLIST (DIFFERENCE 3 1.0))
==> (FLOAT)
|
|
|
|
|
|
|
|
|
Функция DIVIDE (отсутствующая у Лаврова и Силагадзе) вычисляет частное от деления
значения первого аргумента на значение второго. Аргументов должно быть ровно два. Тип аргументов
может быть FIXED или FLOAT. При вычислении частного значения типа FIXED
автоматически приводится к типу FLOAT. Результат всегда имеет тип FLOAT.
Если абсолютная величина делителя оказывается меньше 1.0D-300, то возникает ошибка "Деление
на нуль". В целях упрощения вместо вызова (DIVIDE ...) допустимо писать
(/ ...).
Следует обратить внимание на то, что функция DIVIDE не предназначена для целочисленного
деления; для этого существуют функции QUOTIENT (частное) и REMAINDER (остаток).
Примеры вызова:
(/ 1 2)
==> 0.5
(/ -6 0.5)
==> -12.0
|
|
|
|
|
|
|
|
|
Функции DO и DO* - это самые общие функции организации циклов в Лиспе.
Тип функций, естественно - FSUBR. Функции отсутствуют у Лаврова и Силагадзе,
а в HomeLisp реализованы только в 13-й редакции ядра.
Общий синтаксис функций таков:
(DO/DO* (
(переменная1 значение1 шаг1)
(переменная2 значение2 шаг2)
…
(переменнаяn значениеn шагn)
)
(условие_окончания форма_ок1 форма_ок2 … форма_окm)
(форма1) (форма2) … (формаk)
)
|
Функции выполняется следующим образом:
1. В текущий лексический контекст добавляются переменные цикла
(переменная1, переменная2 ... переменнаяn).
Им присваиваются соответствующие значения. При этом для функции DO
переменные 1 - n вычисляются "одновременно" (как в LET), а для функции
DO* - "параллельно" (как в LET*).
2. Вычисляется условие_окончания. Если оно истинно (т.е. не есть Nil),
то вычисляются формы окончания - форма_ок1 , форма_ок2 … форма_окm
Результат вычисления последней формы возвращается как результат DO/DO*.
3. Если условие окончания ложно, вычисляется тело цикла
- формы: (форма1) (форма2) … (формаk).
4. Всем переменным
(переменная1 , переменная2 … переменнаяn)
присваиваются новые значения путем вычисления соответствующих форм
(шаг1 , шаг2 … шагn)
и происходит переход к п.2.
Все это проиллюстрируем примерами:
(DO (
(i 1 (+ i 1))
(j 1 (+ j 1)))
((> j 5) (printline 'ok) (printline 'ok) (printline 'ok))
(print 'i=) (print i) (prints " ") (print 'j=) (printline j)
)
i=1 j=1
i=2 j=2
i=3 j=3
i=4 j=4
i=5 j=5
ok
ok
ok
==> ok
|
Еще один пример:
(DO (
(i 1 (+ i 1))
(j (+ 1 i) (+ j 1)))
((> j 5) (printline 'ok))
(print 'i=) (print i) (prints " ") (print 'j=) (printline j)
)
Символ i не имеет значения (не связан).
==> ERRSTATE
|
Приведенный выше пример оканчивается ошибкой, поскольку при вычислении начального
значения переменной j, переменная i еще недоступна. Но если вместо DO
вызвать DO*, то ошибки не возникнет:
(DO* ((i 1 (+ i 1))
(j (+ 1 i) (+ j 1)))
((> j 5) (printline 'ok))
(print 'i=) (print i) (prints " ") (print 'j=) (printline j)
)
i=1 j=2
i=2 j=3
i=3 j=4
i=4 j=5
ok
==> ok
|
Если при вызове функции DO форма инициализации одной из переменных цикла
использует предыдущую переменную, а эта переменная создана ранее (до вызова DO),
то ошибка не возникнет, а будет использовано значение этой существующей переменной.
Более того, если функции DO/DO* используют существующие переменые (лексические или глобальные),
то после возврата из функции их значения сохраняются. Вот пример, демонстрирующий, причину
сохранения лексических переменных:
(let ((i 111) (j 222))
(do ((i 1 (+ i 1))
(j 1 (+ j 1)))
((> j 3) (printline 'ok))
(varlist)
)
(printline i)
(printline j)
)
+------------------+---------+----------+
| Имя переменной | Тип | Значение |
+------------------+---------+----------+
|i |Лексич. |1 |
|j |Лексич. |1 |
|j |Лексич. |222 |
|i |Лексич. |111 |
+------------------+---------+----------+
+------------------+---------+----------+
| Имя переменной | Тип | Значение |
+------------------+---------+----------+
|i |Лексич. |2 |
|j |Лексич. |2 |
|j |Лексич. |222 |
|i |Лексич. |111 |
+------------------+---------+----------+
+------------------+---------+----------+
| Имя переменной | Тип | Значение |
+------------------+---------+----------+
|i |Лексич. |3 |
|j |Лексич. |3 |
|j |Лексич. |222 |
|i |Лексич. |111 |
+------------------+---------+----------+
ok
111
222
==> 222
|
А вот пример, показывающий, почему сохраняются значения глобальных переменных:
(setq i 111)
==> 111
Создана глобальная переменная i
(setq j -111)
==> -111
Создана глобальная переменная j
(do ((i 1 (+ i 1))
(j 1 (+ j 1)))
((> j 3) (printline 'ok))
(varlist)
)
+------------------+---------+----------+
| Имя переменной | Тип | Значение |
+------------------+---------+----------+
|i |Лексич. |1 |
|j |Лексич. |1 |
|j |Глобальн.|-111 |
|i |Глобальн.|111 |
+------------------+---------+----------+
+------------------+---------+----------+
| Имя переменной | Тип | Значение |
+------------------+---------+----------+
|i |Лексич. |2 |
|j |Лексич. |2 |
|j |Глобальн.|-111 |
|i |Глобальн.|111 |
+------------------+---------+----------+
+------------------+---------+----------+
| Имя переменной | Тип | Значение |
+------------------+---------+----------+
|i |Лексич. |3 |
|j |Лексич. |3 |
|j |Глобальн.|-111 |
|i |Глобальн.|111 |
+------------------+---------+----------+
ok
==> ok
i
==> 111
j
==> -111
|
В заключение следует сказать о том, что если при вызове DO/DO* задать
две или более одинаковые переменные цикла, то возбуждается состояние
ошибки (переменная выделена красным):
(do ((i 1 (+ i 1))
(i 2 (+ i 3)))
((> i 10) 'ok) (varlist)
(printline i)
)
DO: повторение имени локальной переменной
==> ERRSTATE
|
Разработчик полагает, что вызовы DO/DO*, подобные приведенному выше,
являются бессмысленными. Отчасти это подтверждается тем обстоятельством, что
аналогичный вызов в двух известных системах XLISP и LispWorks
работают по-разному. А именно вот так:
LispWorks:
(do ((i 1 (+ i 1))
(i 1 (+ i 3)))
((> i 10) 'ok)
(print i)
)
1
4
7
10
OK
XLISP:
(do ((i 1 (+ i 1))
(i 1 (+ i 3)))
((> i 10) 'ok)
(print i)
)
1
2
3
4
5
6
7
8
9
10
OK
|
Очевидно, что в LispWorks приращение переменной цикла выполняет вторая форма приращения,
а в XLISP - первая. Поскольку непонятно, какая схема "правильная", то проще предотвратить
задание двух одинаковых переменных цикла...
|
|
|
|
|
|
|
|
Функция DOLIST (типа FSUBR), отсутствующая у Лаврова и Силагадзе, реализована
только в 13-м ядре
HomeLisp. Функция организует "пробег" переменной по заданному списку.
В современных языках программирования такую организацию цикла принято называть
циклом "for each".
Синтаксис вызова функции DOLIST :
(dolist (итератор (список) результат)
(форма1)
(форма2)
…
(формаn)
)
|
Функция последовательно присваивает переменной-итератору значения элементов списка,
после чего выполняется тело цикла (форма1) - (формаn).
После завершения функция DOLIST возвращает результат, заданный формой результат.
Вот пример, поясняющий все сказанное:
(dolist (ite '(1 2 3 4 5 6 7 8 9 10) 'Ok)
(printline (fact ite))
)
1
2
6
24
120
720
5040
40320
362880
3628800
==> ok
|
Естественно, вызовы функций DOLIST могут быть вложенными. При этом
допустимо использовать одну и ту же переменную-итератор (ситуация, немыслимая
в традиционных языках программирования!). Правда, в этом случае во внутреннем цикле
не будет доступно "внешнее" значение итератора:
(dolist (ite '(1 2 3) 'ok)
(dolist (ite '(4 5 6) 'ok)
(printline ite)))
4
5
6
4
5
6
4
5
6
==> ok
|
Тот же пример с двумя различными переменными цикла дает совершенно предсказуемый
результат:
(dolist (ite1 '(1 2 3) 'ok)
(dolist (ite2 '(4 5 6) 'ok)
(print ite1) (prints " ") (printline ite2)))
1 4
1 5
1 6
2 4
2 5
2 6
3 4
3 5
3 6
==> ok
|
|
|
|
|
|
|
|
|
Функция DOTIMES (реализованная только в 13-м ядре и отсутствующая
у Лаврова и Силагадзе) принадлежит к классу FSUBR. Эта функция обеспечивает выполнение блока кода заданное
число раз. Синтаксис вызова функции следующий:
(dotimes (переменная_цикла
число_повторений
результат)
(форма1)
(форма2)
…
(формаn)
)
|
Вычисление происходит так. Переменная цикла последовательно получает значения от 0 до
значения число_повторений-1. При каждом значении переменной цикла последовательно
вычисляются формы (форма1) - (формаn). По завершении цикла
вычисляется форма-результат и возвращается в качестве результата DOTIMES.
Вот как это выглядит:
(dotimes
(i 5 t)
(print 'i=)
(printline i)
)
i=0
i=1
i=2
i=3
i=4
==> T
|
Достаточно интересно то, что переменную цикла в теле цикла можно менять! Никакого
зацикливания при этом не произойдет:
(dotimes
(i 5 t)
(setq i -1)
(print 'i=)
(printline i)
)
i=-1
i=-1
i=-1
i=-1
i=-1
==> T
|
Для досрочного выхода из цикла можно использовать функцию RETURN:
(dotimes (i 10 t)
(print 'i=)
(printline i)
(if (= i 7) (return 'ok) nil)
)
i=0
i=1
i=2
i=3
i=4
i=5
i=6
i=7
==> ok
|
В этом случае в качестве результата возвращается результат вызова RETURN.
|
|
|
|
|
|
|
|
Функция DOTPRINT (отсутствующая у Лаврова и Силагадзе) позволяет напечатать внутреннюю (точечную) форму
значения своего аргумента. Если аргумент - атом, поведение функции не отличается от поведения функции PRINT.
Примеры вызова:
(dotprint '(a b c d))
(a . (b . (c . (d . NIL))))
==> (a b c d)
(dotprint '(a))
(a . NIL)
==> (a)
|
|
|
|
|
|
|
|
|
Функция EQ сравнивает два своих аргумента. Если один или оба аргумента функции
EQ не являются атомами, функция вернет NIL. Если же оба аргумента функции - атомы,
то функция сравнивает их. Если атомы совпадают, возвращается T, в противном случае
возвращается NIL. Вот несколько примеров:
(eq 1 2)
==> NIL
(eq 1 1)
==> T
(eq 2 (+ 1 1))
==> T
(eq 'a 'b)
==> NIL
(eq _pi 3.14)
==> NIL
(eq _pi 3.1415926535)
==> T
(eq 'a 'a)
==> T
(setq x 1)
==> 1
(eq x 1)
==> T
|
Функция EQ принадлежит к классу SUBR, поэтому аргумент (+ 1 1)
перед передачей в функцию EQ будет вычислен (и заменен атомом 2). В последнем
примере x - переменная, имеющая значение 1. Вот почему в обоих случаях функция EQ
дает T.
Следует обратить особое внимание на то, что функция EQ не пригодна для сравнения
произвольных S-выражений на идентичность. Для этого служит функция EQUAL, принадлежащая
библиотеке дополнительных функций. Разумеется, функция EQUAL использует
функцию EQ.
|
|
|
|
|
|
|
|
Функция EQL, отсутствующая у Лаврова и Силагадзе, требует двух аргументов. Если оба аргумента
представляют собой один и тот же объект (неважно, атом или список), то функция возвращает T.
В противном случае функция возвращает Nil. Вот несколько примеров вызова функции EQL:
(eql 1 1)
==> T
(eql 1 2)
==> NIL
(eql '(1 2) '(1 2))
==> NIL
(equal '(1 2) '(1 2))
==> T
(setq z '(1 2))
==> (1 2)
(setq w (list z z))
==> ((1 2) (1 2))
(eql z (car w))
==> T
(eql z (cadr w))
==> T
|
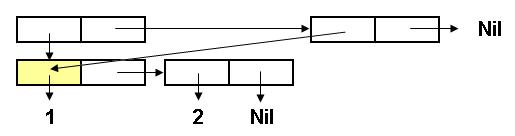
Первые два примера воспринимаются вполне естественно. А вот третий пример может вызвать удивление.
Действительно, ведь значения обоих аргументов EQL представлены одним и тем же
списком - (1 2). Почему же функция показывает, что списки различаются? Дело в том,
функция EQL не проверяет, состоят ли списки-аргументы из одних и тех же элементов (как
приведеная ниже функция EQUAL). Функция EQL проверяет факт совпадения адресов
значений первого и второго аргумента. Чтобы лучше уяснить происходящее, читателю предлагается
рассмотреть внутреннюю структуру списка аргументов вызова (EQL '(1 2) '(1 2)).
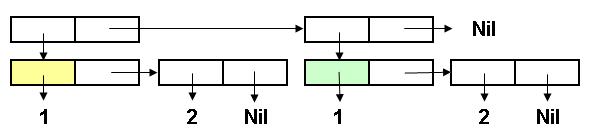
Функция EQL сравнивает адреса списочных ячеек, залитых желтым и зеленым цветом на идентичность.
Из рисунка видно, что хотя содержимое этих ячеек одинаково, но адреса их будут различаться (отюда и
результат). А вот функция EQUAL (написанная на Лиспе) рекурсивно сравнивает именно содержимое, поэтому
результат (EQUAL '(1 2) '(1 2)) оказывается равным T.
Совсем по-другому будет обстоять дело в том случае, когда сначала переменной z присваивается значение
(1 2), затем переменной w присваивается значение выражения (LIST z z). Значение переменной
z будет иметь такой вид:
Теперь (CAR w) и (CADR w) представляют собой одну и ту же ячейку. В этом случае
функция EQL вернет T.
|
|
|
|
|
|
|
|
Функция EVAL вычисляет свой аргумент (который может быть атомом или списком).
Вычисление заключается в следующем:
Если аргументом является числовая и строковая константа {1, 2.5, &H15, "abc"}, имеющих в списке свойств индикаторы
FIXED, FLOAT, BITS или STRING соответственно, значением является сама константа.
Если аргументом является атом с индикатором APVAL, то в качестве значения атома выдается
значение его определяющего выражения. В частности, для встроенных констант (_Pi, _E, _Ver) значением являются 3.1415926535, 2.718281828 и "HomeLisp Вер. N.M.KK (Файфель Б.Л.)"
соответственно. Полезно заглянуть в список объектов и найти там указанные выше константы. Будет отчетливо видно,
что у этих констант в списке свойств имеется индикатор APVAL, а определяющее выражение представляет собой константу
соответствующего типа.
Если аргументом является атом-переменная (она создается вызовом SETQ), в качестве значения EVAL выдается значение выражения,
присвоенного атому.
Если аргументом является список, то его первый элемент рассматривается как имя функции, в все остальные элементы -
как список аргументов этой функции. Отсюда следует, что не каждый список можно "вычислить" с помощью функции EVAL. Например,
список (a b c) можно вычислить только если a - функция c двумя аргументами.
Вот необходимые примеры:
(eval 1)
==> 1
(eval _Pi)
==> 3.1415926535
(eval a)
==> Символ "a" не имеет значения (не связан).
(setq a '(x y z))
==> (x y z)
(eval a)
==> Символ "x" не имеет значения (не связан).
(setq a ''(1 2 3))
==> (QUOTE (1 2 3))
(eval a)
==> (1 2 3)
|
Действие функции EVAL противоположно действию функции QUOTE. Это означает,
что значение выражения (EVAL 'Нечто) равно выражению Нечто.
Следует обратить внимание на одну тонкость: атом может быть переменной и одновременно являться
именем функции (т.е. иметь в списке свойств один из индикаторов EXPR, FEXPR или
MACRO). Дело в том, что определяющее выражение и значение хранятся в разных местах и
нисколько не мешают друг другу. Вот пример, иллюстрирующий сказанное выше:
(setq myFunct 777)
==> 777
(defun myFunct (x y) (+ (* x x) (* y y)))
==> myFunct
(eval myFunct)
==> 777
(myFunct 3 4)
==> 25
|
Замечание.
В 13-й редакции ядра функция EVAL имеет важную
особенность: вычисление EVAL всегда происходит в пустом лексическом и текущем
глобальном контекстах. Это соответствует спецификации Common Lisp. Вот пример,
поясняющий сказанное:
(let ((a 111)) (varlist) (eval 'a))
+-----------------+---------+------------+
| Имя переменной | Тип | Значение |
+-----------------+---------+------------+
|a |Лексич. |111 |
+-----------------+---------+------------+
Внутри LET: Assoc: Символ a не имеет значения (не связан).
==> ERRSTATE
(setq a 222)
==> 222
Создана глобальная переменная a
(let ((a 111)) (varlist) (eval 'a))
+-----------------+---------+------------+
| Имя переменной | Тип | Значение |
+-----------------+---------+------------+
|a |Лексич. |111 |
|a |Глобальн.|222 |
+-----------------+---------+------------+
==> 222
|
Видно, что при первом вызове значение лексической переменной a игнорируется,
а при втором вызове берется значение глобальной переменной.
|
|
|
|
|
|
|
|
Функция ERRORMESSAGE не требует аргументов. Она возвращает активное сообщение об ошибке в виде
текстовой строки. Функцию имеет смысл использовать только совместно с функцией TRY в блоке,
размещенном после атома EXCEPT. Если вызвать функцию ERRORMESSAGE в другом контексте
(даже сразу же после вычисления, завершившегося ошибкой), то она вернет пустую строку.
Вот примеры вызова ERRORMESSAGE:
(/ 1 0)
DIVIDE - деление на нуль
==> ERRSTATE
(errormessage)
==> ""
(try (/ 1 0)
except
(prog nil (say (strcat "Ошибка: " (errormessage))) (return 0))
)
==> 0
|
Здесь при вызове ERRORMESSAGE сразу после ошибки, выдается пустая строка.
А при вызове ERRORMESSAGE посредством конструкции TRY-EXCEPT выводится
диалоговое окно:
|
|
|
|
|
|
|
|
Функция EXPLODE(отсутствующая у Лаврова и Силагадзе), принимает один обязательный аргумент, значение которого должно
быть атомом. Функция возвращает одноуровневый список, состоящий из символов, состоавлющих
имя атома. Атом как бы "врывается", разлетаясь на отдельные симвлы (отсюда и название).
Имеется единственная тонкость - некоторые символы, приведенные в расположенной ниже таблице,
заменяются на особые атомы.
| Символ в исходном атоме |
Заменяющий символ |
| Двойная кавычка (") |
&DQ |
| Точка (.) |
&DT |
| Апостроф (') |
&AP |
| Пробел |
&BL |
| Обратный апостроф (`) |
&BQ |
Вот примеры вызова:
(explode 'explode)
==> (e x p L O d e)
(explode 1234)
==> (1 2 3 4)
(explode (fact 8))
==> (4 0 3 2 0)
(explode (/ 1 3))
==> (0 &DT 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3)
(explode "abc")
==> (&DQ a b c &DQ)
(explode 'abc)
==> (a b c)
|
Функция EXPLODE обеспечивает чисто лисповский подход к анализу символьной
информации (без привлечения строковых функций).
|
|
|
|
|
|
|
|
|
|
Функция EXPT принимает два аргумента x и y и вычисляет выражение
xy. При этом действуют следующие соглашения:
Если оба аргумента имеют тип FIXED и показатель степени
(y) положителен, то результат будет иметь тип FIXED и соответствующий знак;
(^ 2 3)
==> 8
(^ 2 100)
==> 1267650600228229401496703205376
(^ -2 100)
==> 1267650600228229401496703205376
(^ -2 101)
==> -2535301200456458802993406410752
|
Если оба аргумента имеют тип FIXED и показатель степени
(y) отрицателен, то выдается сообщение "Попытка возведения числа типа FIXED в отрицательную
степень" и функция не вычисляется. Это соглашение может показаться несколько странным,
но любое целое число в целой отрицательной степени есть число рациональное (не FIXED),
поэтому принято решение разрешить возведение в целую отрицательную степень только чисел
типа FLOAT:
(^ 4 -2)
==> Попытка возведения числа FIXED в отрицательную степень
(^ 4.0 -2)
==> 0.0625
|
Положительное число типа FLOAT можно возвести в степень любого
типа и любого знака. В обоих случаях результат будет иметь тип FLOAT:
(^ 625.0 0.5)
==> 25.0
(^ 625.0 -0.5)
==> 0.04
|
Отрицательное число типа FLOAT можно возвести только в целую положительную или отрицательную степень.
В обоих случаях результат будет иметь тип FLOAT:
(^ -625.0 -4)
==> 6.5536E-12
(^ -625.0 4)
==> 152587890625.0
|
Попытка возвести отрицательное число в вещественную степень любого
знака вызывает ошибку:
(^ -625 4.0)
==> Попытка возведения отрицательного числа в вещ. степень
(^ -625 -4.0)
==> Попытка возведения отрицательного числа в вещ. степень
(^ -625.0 -4.0)
==> Попытка возведения отрицательного числа в вещ. степень
|
И, разумеется, попытка возвести ноль в нулевую или
отрицательную степень вызовет ошибку. Ненулевое число в нулевой степени равно
единице.
|
|
|
|
|
|
|
|
Функция FIX принимает один аргумент. Если значение
аргумента имеет тип FIXED, функция возвращает значение
аргумента. Если же значение аргумента имеет тип FLOAT,
то функция возвращает значение аргумента, округленное до
ближайшего целого. В любом случае тип результата - всегда
FIXED. Вот примеры, иллюстрирующие сказанное:
(FIX 67)
==> 67
(FIX -6.6)
==> -7
(FIX '(1 2 3))
Aргумент FIX - не атом
==> ERRSTATE
(FIX (+ 1 2.5))
==> 4
|
|
|
|
|
|
|
|
|
Функция-предикат FIXEDP (у Лаврова и Силагадзе она
называется FIXP) принимает один аргумент. Если значение
аргумента имеет тип FIXED, функция возвращает T,
в противном случае - Nil
(FIXEDP 67)
==> T
(FIXEDP (+ 5 9))
==> T
(FIXEDP '(1 2 3))
==> Nil
(FIXEDP (+ 1 2.5))
==> Nil
|
В последнем случае результат вычисления (+ 1 2.5) будет иметь тип FLOAT.
|
|
|
|
|
|
|
|
Функция FIX2BIT (отсутствующая у Лаврова и Силагадзе) принимает один аргумент, значение которого
должно иметь тип FIXED. Если значение аргумента (как знаковое целое) может быть преобразовано
к типу BITS (уместиться в 4 байта), то функция возвращает значение аргумента, как битовую константу.
В противном случае выдается сообщение о невозможности преобразования.
(FIX2BIT 67)
==> &H43
(FIX2BIT -1)
==> &HFFFFFFFF
(FIX2BIT 123456789123456789)
==> Значение аргумента FIX2BIT за пределами допустимого диапазона
(FIX2BIT (+ 1 2 3 4.5))
==> Аргумент FIX2BIT - не имеет тип FIXED
|
В последнем случае результат вычисления (+ 1 2 3 4.5) будет иметь тип FLOAT; это вызывает сообщение
об ошибке.
|
|
|
|
|
|
|
|
Функция FIX2FLO (отсутствующая у Лаврова и Силагадзе) принимает один аргумент, значение которого
должно иметь тип FIXED. Если значение аргумента не превышает по модулю 10300,
функция преобразует значение аргумента к типу FLOAT. Если же значение аргумента превышает по модулю 10300,
то выдается сообщение об ошибке (переполнение). Поскольку в HomeLisp диапазон значений
данных типа FIXED значительно шире, чем типа FLOAT, то в процессе преобразования происходит потеря
большего количества значащих цифр (остется 15). Вот несколько примеров:
(FIX2FLO 67)
==> 67.0
(FIX2FLO (fact 100))
==> 9.33262154439442E+157
(FIX2FLO (fact 200))
Переполнение при вызове FIX2FLO
==> ERRSTATE
|
В предпоследнем случае промежуточный результат вычисления (fact 100) имеет вид:
93326215443944152681699238856266700490715968264381621468592963895217599993229915608941463976156518286253697
920827223758251185210916864000000000000000000000000
Это одно длинное число! После его преобразования в тип FLOAT получается результат
9.33262154439442E+157. А в последнем случае промежуточный результат вычисления (fact 200)
слишком велик для типа FLOAT.
|
|
|
|
|
|
|
|
Функция FLO2FIX (отсутствующая у Лаврова и Силагадзе) принимает один аргумент, значение которого
должно иметь тип FLOAT. Функция преобразует результат к типу FIXED. При этом
дробное число округляется до ближайшего целого. Для чисел с большим десятичным порядком
функция оставляет 15 значаших цифр значения аргумента и добавляет нужное количество нулей.
Вот несколько примеров:
(FLO2FIX 67.6)
==> 68
(FLO2FIX (* 1000000.0 _pi))
==> 3141593
(FLO2FIX (FIX2FLO (FACT 100)))
==> 93326215443944200000000000000000000000000000000000
00000000000000000000000000000000000000000000000000
00000000000000000000000000000000000000000000000000
00000000
|
В последнем примере отчетливо видно, как после цепочки преобразований FIXED -> FLOAT -> FIXED
у результата остается только 15 верных значащих цифр.
|
|
|
|
|
|
|
|
Функция FLO2STR (отсутствующая у Лаврова и Силагадзе) принимает один аргумент, значение которого
должно иметь тип FLOAT. Функция преобразует результат к типу STRING. Делается это
очень просто - символьное изображение числа заключается в двойные кавычки.
Вот несколько примеров:
(flo2str _Pi)
==> "3.14159265358979323846"
(flo2str (sin _pi))
==> "1.22460635382238E-16"
(flo2str 1)
Аргумент FLO2STR не имеет тип FLOAT
==> ERRSTATE
(flo2str 1.0)
==> "1.0"
(flo2str 6.02E+23)
==> "6.02E+23"
|
Видно, что попытка дать на вход функции FLO2STR число типа FIXED, вызывает ошибку.
|
|
|
|
|
|
|
|
Функция-предикат FLOATP (отсутствующая у Лаврова и Силагадзе) принимает один аргумент.
Если значение аргумента имеет тип FLOAT, функция возвращает T, в противном случае - Nil
Вот набор примеров вызова FLOATP:
(FLOATP 67)
==> Nil
(FLOATP 67.0)
==> T
(FLOATP (+ 5 9))
==> Nil
(FLOATP (+ 5.0 9))
==> T
(FLOATP '(1 2 3))
==> Nil
|
В третьем случае результат вычисления (+ 5 9) будет иметь тип FIXED.
|
|
|
|
|
|
|
|
Функция FORMAT (отсутствующая у Лаврова и Силагадзе) принимает два аргумента.
Первый аргумент должен быть числового типа (FIXED или FLOAT). Второй
аргумент должен иметь строковый тип. Функция преобразует значение первого аргумента
в строку символов, используя значение второго аргумента как строку формата.
Строка формата может содержать следующие символы:
|
Символ формата
|
Вызываемое действие
|
|
0
|
В выходной строке в соответствующем
знакоместе будет выведена цифра. Если в этом знакоместе располагается пробел,
то он заменяется нулем.
|
|
#
|
В выходной строке в соответствующем
знакоместе будет выведена цифра или пробел (если цифры первого аргумента "не
достают" до соответствующей позиции.
|
|
E+
|
В этом месте выводится десятичный
порядок, причем, если порядок положителен, то перед значением
порядка ставится плюс.
|
|
E-
|
В этом месте выводится десятичный
порядок, причем, если порядок положителен, то перед значением
порядка плюс не ставится.
|
Вот набор примеров вызова FORMAT:
(format 6000.06 "######0.00")
==> "6000.06"
(format 6000.06 "000000.00")
==> "006000.06"
(format 6000.06 "0.00E+")
==> "6.00E+3"
|
По сути дела функция FORMAT выполняет обратное действие по отношению к
функциям STR2FIX и STR2FLO, но с дополнительными возможностями
форматирования.
|
|
|
|
|
|
|
|
Функционал FUNCALL (отсутствующий у Лаврова и
Силагадзе) принимает произвольное количество аргументов. Первый
аргумент должен быть атомом или лямбда-выражением. Последующие
аргументы могут быть произвольными. Выполнение функции
FUNCALL заключается в применении первого аргумента (как
функции) к значениям последующих аргументов. Вызов
FUNCALL вида:
(FUNCALL fn x1
x2 ... xn)
эквивалентен
вызову:
(fn x1 x2 ...
xn)
Вот примеры вызова FUNCALL:
(funcall 'times 1 2 3 4 5)
==> 120
(setq sum 'Plus)
==> PLUS
(funcall sum 1 2 3 4)
==> 10
(funcall (car '(plus difference times divide)) 66 55)
==> 121
(funcall (cadr '(plus difference times divide)) 66 55)
==> 11
(funcall (caddr '(plus difference times divide)) 66 55)
==> 3630
(setq cons 'divide)
==> DIVIDE
(funcall cons 2 3)
==> 0.666666666666667
(funcall 'cons 2 3)
==> (2 . 3)
(funcall '(lambda (x y) (+ (* x x) (* y y))) 3 4)
==> 25
|
Следует обратить внимание на то, что, поскольку все аргументы
функции FUNCALL вычисляются, то можно вводить синонимы
имен функций. Так, в одном из приведенных выше примеров, атому
CONS присвоено значение DIVIDE. Это имеет
следствием то, что при подстановке первым аргументом
переменной CONS выполняется деление. Если же первым
аргументом этого же вызова подставить не переменную, а
атом CONS, то происходит консолидация (образование
точечной пары). Функция FUNCALL похожа на описанную выше
функцию APPLY; отличие заключается в том, что аргументы,
которые у функции FUNCALL обрабатываются "россыпью", у
функции APPLY должны быть объединены в список.
|
|
|
|
|
|
|
|
Конструкция FUNCTION предназначена для задания т.н. функционального аргумента.
Следует отметить, что эта конструкция имеет существенные отличия в разных редакциях
ядра HomeLisp. Далее сначала описывается применение FUNCTION в
11-й редакции ядра, а затем - применение FUNCTION в
13-й редакции ядра HomeLisp.
|
Конструкция в 11-й редакции ядра HomeLisp
|
Пусть читатель
обратит внимание на термин "конструкция" - хотя слово FUNCTION употребляется в виде
(FUNCTION имя_функционального_аргумента), эта запись лишь внешне напоминает лисповский вызов функции
с одним аргументом. Цель описываемой конструкции состоит не в вычислении.
Чтобы понять назначение описываемой конструкции, рассмотрим функцию:
(defun Calc (f x)
(f x)
)
|
Эта функция имеет два аргумента: первый аргумент - имя функции, второй - произвольный список.
Она вызывает из своего тела функцию, имя которой задано первым аргументом, а список параметров -
вторым.
Аргумент, c которым при вызове связывается функция, а не переменная,
называется функциональным. А функция, использующая функциональные аргументы, называется
функционалом. Таким образом, Calc - функционал.
Попробуем вызвать этот функционал так: (Calc Car '(1 2 3)). Казалось бы этот
вызов должен преобразоваться в вызов (Car '(1 2 3)) и, естественно, дать в результате
1. Однако результат будет обескураживающим:
(calc car '(1 2 3))
==> Символ "CAR" не имеет значения (не связан).
|
Но, в сущности, все так и должно быть! Функция Calc имеет тип EXPR; ее аргументы
вычисляются. Первый аргумент - атом Car. При вычислении он будет рассматриваться как
переменная. Естественно, переменной Car нет в системе. Отсюда и приведенный выше
удивительный результат. Вот для того, чтобы сообщить ядру языка, что тот или иной аргумент
является не переменной, а именем функции (типа SUBR, FSUBR или EXPR) и служит
специальный вызов (Function xxx). Таким образом, правильно вызывать функцию
Calc следует так:
(calc (function car) '(1 2 3))
==> 1
(calc (function cdr) '(1 2 3))
==> (2 3)
|
Справедливости ради следует отметить, что функцию Calc можно вызвать и более простым
способом (без использования конструкции Function). А именно, вот так:
(calc 'car '(1 2 3))
==> 1
(calc 'cdr '(1 2 3))
==> (2 3)
|
И действительно, второй метод (с использованием квотирования) проще. Но при его использовании
может возникнуть проблема, если функция, которая связывается с функциональным аргументом,
использует свободные переменные. (Так называются переменные, которые не входят в список
параметров функции, но используются в теле функции). Дело в том, что функционал может сделать свободную переменную локальной (включив ее в список
своих параметров или в список параметров функции PROG). Естествено, что в этом случае функционал вправе перед
обращением к функциональному аргументу произвольным образом изменить эту переменную.
Однако, в Лиспе принято, что при вычислении тела определяющего выражения
функции, соответствующей функциональному аргументу, должны использоваться те значения
свободных переменных, которыми они обладали перед началом вычисления функционала. Использование
конструкции (FUNCTION ...) обеспечивает соблюдение этого условия. Рассмотрим примеры.
Следуя книге Лаврова и Силагадзе, введем функцию:
(defun f1 (x) (cond ((null x) y) (t x)))
==> f1
|
Эта функция проверяет значение своего аргумента. Если аргумент равен Nil, функция
возвращает значение свободной переменной y. В противном случае функция
возвращает значение своего аргумента. Заведем переменую y:
Переопределим функционал Calc следующим образом:
(defun calc (f x) (prog (y)
(setq y 888)
(print y)
(terpri)
(return (f x))
)
)
==> calc
|
Мы сделали переменную y локальной в теле функционала (связали переменную). При выполнении функционала
переменной y сначала присваивается значение 888, затем оно выводится (для
контроля), и, наконец, происходит обращение к функциональному аргументу f. Теперь
вызовем функционал Calc:
(Calc (function f1) nil)
888
==> -111
|
Обратите внимание, что хотя значение переменной y в теле функционала равно
888, при вычислении f1 использовано старое значение (то, которое переменная
y имела до входа в тело функционала).
Если же обратиться к функционалу без использования конструкции (FUNCTION ...) (с квотированием),
то результат будет другой:
(Calc 'f1 nil)
888
==> 888
|
Здесь использовано последнее (активное) значение переменной y. Чтобы понять, за счет
чего при вызове (FUNCTION ...) используется неактивное значение переменной, имеет
смысл заглянуть в дампы вычислений. При вычислении выражения (Calc (function f1) nil)
перед обращением к функциональному аргументу ассоциативный список будет находиться в состоянии:
..................... Ассоциативный список:
.....................
..................... 6 -> (x)
..................... 5 -> (NIL 1)
..................... 4 -> (y . 888)
..................... 3 -> (x)
..................... 2 -> (f FUNARG f1 1)
..................... 1 -> (y . -111)
|
От пятого элемента переброшен "мостик" к первому
элементу. При вычислении значения y ассоциативный список
просматривается от последнего элемента к первому, до тех пор,
пока не будет найден нужный элемент или не будет достигнуто
начало списка. Если встречается "мостик" (элемент вида
(NIL n), где n - номер следующего элемента), то
поиск продолжается с элемента n. Из приведенного выше
рисунка видно, что при поиске значения переменной y
будет получено значение -111, т.к. четвертый элемент
находится "под мостиком" и обходится.
Если же
вызвать функционал Calc с квотированием - (Calc 'f1
nil), то перед обращением к функциональному аргументу
ассоциативный список будет находиться в состоянии:
................... Ассоциативный список:
...................
................... 5 -> (x)
................... 4 -> (y . 888)
................... 3 -> (x)
................... 2 -> (f . f1)
................... 1 -> (y . -111)
|
"Мостика" нет, и переменная y получает активное значение 888.
Теперь понятно, что если функциональный аргумент есть функция типа SUBR/FSUBR,
то можно использовать квотирование при вызове (поскольку функция SUBR/FSUBR не
используют переменных Лиспа). Аналогичным образом обстоит дело и в случае, если
функциональный аргумент есть функция класса EXPR, которая не использует значения
свободных переменных. Если же функциональный аргумент есть функция класса EXPR, которая
использует значения свободных переменных, а функционал эти переменные локализует, то
использование конструкции (FUNCTION ...) при вызове необходимо.
Если же функционал просто
меняет значения уже существующих свободных переменных (без локализации их в функционале),
то конструкция (FUNCTION ...) не поможет - при вычислении функционального аргумента
будут взяты измененные значения переменных. Чтобы убедиться в этом, переопределим функционал
Calc так:
(defun calc (f x) (prog (Nil)
(setq y 888)
(print y)
(terpri)
(return (f x))
)
)
==> calc
|
Это определение отличается от предыдущего тем, что переменная y не локализована
в PROG-блоке (т.е. свободна). Теперь оба вызова (с конструкцией FUNCTION и
с квотированием) дадут одинаковый результат:
(Calc (function f1) nil)
888
==> 888
(Calc 'f1 nil)
888
==> 888
|
Желающие могут заглянуть в дамп и убедиться, что поскольку в ассоциативном списке
не создается локальная переменная y, то функционал и вызываемая функция используют
свободную переменную (значение которой изменяется функционалом перед вызовом).
Функционал не может быть функцией класса FEXPR. Точнее, при обращении к функции типа
FEXPR, не допустимо задание функционального аргумента в виде (FUNCTION F).
Как следует из вышеизложенного,
при обработке списка параметров функции типа EXPR появление конструкции
(FUNCTION ff) сразу же порождает в ассоциативном списке запись вида
(f FUNARG ff n), где n - фиксатор заполнения ассоциативного
списка на момент задания функционального аргумента. После этого ассоциативный
список может продолжать заполняться, но перед вычислением f возникнет "мостик" и
будут взяты правильные значения свободных переменных.
Если же попытаться выполнить функцию класса FEXPR с функциональным аргументом
(FUNCTION f), то конструкция
(FUNCTION f) будет вычисляться уже в процессе обработки тела функции.
При этом момент фиксации состояния ассоциативного списка будет упущен.
В реализации HomeLisp при попытке выполнить
функционал класса FEXPR c аргументом вида (FUNCTION F)
выдается соответствующее сообщение.
В 13-й редакции ядра HomeLisp конструкция
FUNCTION порождает замыкание (определение функции с зафиксированными связями
свободных переменных). Чтобы убедиться в этом, рассмотрим следующий пример:
(defun f (x) (* x y))
==> f
(f 7)
Assoc: Символ y не имеет значения (не связан).
==> ERRSTATE
(setq ff (let ((y 111)) (function f)))
==> (CLOSURE f ((y 111)))
Создана глобальная переменная ff
(funcall ff 7)
==> 777
|
Здесь создается функция f с параметром x и свободной переменной
y. Если вызвать функцию f "просто так", то возникает ошибка,
поскольку переменная y не имеет значения.
Далее переменной ff присваивается замыкание функции
f с зафиксированным значением свободной переменной y (равным 111).
Последующий вызов ff дает предсказуемый результат.
Если вместо вызова (function f) употребить обычное квотирование, то результат
окажется другим:
(setq gg (let ((y 111)) 'f))
==> f
Создана глобальная переменная gg
(funcall gg 7)
Assoc: Символ y не имеет значения (не связан).
==> ERRSTATE
|
Видно, что квотирование не обеспечивает сохранение значений свободных
переменных. Если же завести глобальную переменную y,
то вызов (funcall gg 7) завешится без ошибки, но при вычислении
значения y будет взято "глобальное" значение:
(setq y 222)
==> 222
Создана глобальная переменная y
(funcall gg 7)
==> 1554
|
Если перевычислить выражение (funcall ff 7), то можно убедиться,
что существование глобальной переменной y не окажет никакого
влияния на результат - будет взято ранее зафиксированное значение:
В этом и состоит суть конструкции FUNCTION в 13-й
редакции ядра HomeLisp. Осталось сказать, что по аналогии с использованием
апострофа вместо полной записи функци QUOTE,
запись (FUNCTION any) можно записывать в виде #'any.
|
|
|
|
|
|
|
|
Функция GC вызывает т.н. уборку мусора. Мусор
- это области памяти, которые заняты недоступными ядру Лиспа
или бесполезными структурами. Ниже будет объяснено, что имеется
в виду под недоступностью и бесполезностью. Если
читатель не хочет вникать в суть этих (не слишком простых)
вопросов, он может не читать дальше этот раздел и просто
принять к сведению, что функция GC освобождает память,
занятую мусором и обычно вызывается автоматически, но может
быть вызвана и вручную (для чего предусмотрен пункт меню и
соответствующая кнопка). При автоматическом вызове сборки
мусора пользователь может задать граничный процент
увеличения количества занятых ячеек памяти, по достижении
которого сборка мусора будет включаться автоматически. По
умолчанию это 35% (число достаточно произвольное). Если после
выполнения очередной команды пользователя количество атомов в
системе увеличится на 35 или более процентов, то после
завершения команды и вывода результата будет автоматически
вызвана сборка мусора.
Тем же читателям, которым интересна внутренняя реализация
языка, следует сначала разобраться как HomeLisp хранит и
обрабатывает списки.
Любой список (или точечная пара) в конечном итоге состоит из
атомов. Каждому атому соответствует особый объект -
информационная ячейка атома. Свойства атома
HomeLisp (важнейшим из которых является его имя)
реализованы как свойства объекта (поля). Создать атом - значит
создать его информационную ячейку и занести в ее поля
необходимую информацию. Далее мы будем употреблять понятия
"атом" и "информационная ячейка атома" как синонимы.
Одних информационных ячеек атомов недостаточно для создания
списков произвольной структуры. Ведь список это не просто
неупорядоченная совокупность атомов. Для задания порядка
соединения атомов в списке служат т.н. списочные ячейки.
Списочная ячейка - это тоже объект, важнейшими
свойствами которого являются два указателя. По историческим
причинам они называются a-указатель и
d-указатель. Эти указатели могут ссылаться на
информационные ячейки атомов или другие списочные ячейки. Таким
образом, при создании списков списочные ячейки играют роль
коннекторов.
Для изображения списков обычно используется графическая
нотация, в которой списочные ячейки изображаться
прямоугольниками, разделенными пополам. Будем считать, что
левая половинка прямоугольника содержит a-указатель, а
правая - d-указатель. Стрелка, исходящая из
соответствующей клетки, будет указывать на тот или иной объект
(атом или списочную ячейку). При этом информационные ячейки
атомов не рисуются; стрелки просто указывают на атом. Так,
точечная пара (A . B) графически изображается так:
|
|
|
Внутренее строение точечной пары
|
Список (A B C D) устроен так:

|
|
|
Внутренее строение простого списка
|
А вот как изображается список более сложной структуры ( (A B) C D):
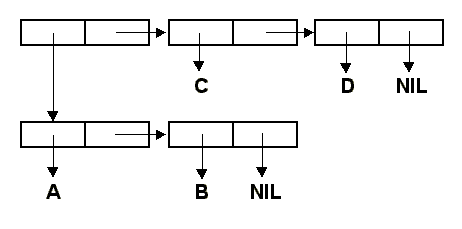
|
|
|
Внутренее строение сложного списка
|
Следует обратить внимание на один достаточно тонкий момент. Механизм создания информационных
ячеек таков, что если возникает необходимость сослаться на атом первый раз, то атом
(т.е. его информационная ячейка) создается. Все последующие вхождения этого атома в
S-выражения порождают ссылки на одну и ту же информационную ячейку. Поэтому, хотя
список (A A A) обычно изображают следующим образом:
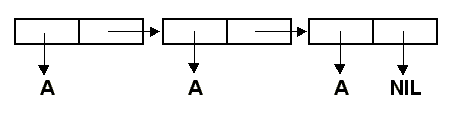
|
|
|
Так изображают список, содержащий одинаковые
атомы.
|
более правильно изображать этот список так:
|
|
|
Информационная ячейка создается один раз. Все
последующие ссылки выполняются на один и тот же атом.
|
Информационные ячейки атомов объединены в коллекцию -
список объектов. В списке объектов располагаются все
атомы Лиспа. После запуска программы в списке объектов
располагаются "стандартные" атомы - Nil (этот атом
обычно бывает первым в списке), T, а также все
индикаторы (APVAL, FIXED, FLOAT, STRING, BITS ), имена
всех встроенных функций (PLUS, DIFFERENCE и т.д.), и ряд
служебных атомов. Кроме того, в списке объектов располагаются
имена Лисп-констант и ссылки на их значения. Информационная ячейка
атома (в системе HomeLisp) устроена заметно сложнее списочной
ячейки. Информационная ячейка включает поле имени атома, поле стандартных
флагов, поле ссылки на определяющее выражение, поле ссылки на
список дополнительных свойств (а также еще ряд дополнительных полей).
Схематично информационную ячейку можно изобразить так:
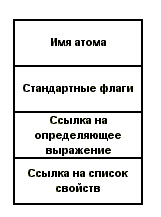
|
|
|
Внутреннее строение информационной ячейки
|
Следует отметить, что поле "Имя атома" хранит строку
переменной длины; поле "Стандартные флаги" представляет
собой 16-битовую логическую шкалу, биты которой используются в
соответствии с приведенной ниже таблицей.
|
Флаг
|
Битовый индикатор
|
|
SUBR
|
0000000000000001
|
|
FSUBR
|
0000000000000010
|
|
EXPR
|
0000000000000100
|
|
FEXPR
|
0000000000001000
|
|
APVAL
|
0000000000010000
|
|
FIXED
|
0000000000100000
|
|
BITS
|
0000000001000000
|
|
STRING
|
0000000010000000
|
|
FLOAT
|
0000000100000000
|
|
MACRO
|
0000001000000000
|
|
WINDOW
|
0000010000000000
|
|
FILE
|
0000100000000000
|
|
BLOB
|
0001000000000000
|
|
COM
|
0010000000000000
|
|
DIALOG
|
0100000000000000
|
|
CONTROL
|
1000000000000000
|
Шесть последних флагов используются для объектов, которые не
являются лисповскими объектами, а служат для работы с
графикой (GRAPHIC WINDOW), файлами (FILE),
большими двоичными объектами (BLOB),
ActiveX-компонентами (COM), диалогов (DIALOG) и
элементов управления (CONTROL). Все эти средства
HomeLisp описываются в соответствующих разделах
руководства.
Поле "Cсылка на определяющее выражение" может
содержать адрес информационной ячейки атома-значения или адрес списка - определяющего выражения
функции. Поле "Cсылка на список свойств" либо пусто, либо содержит ссылку
на список свойств атома.
Покажем теперь, как хранятся определяющие выражения функций. Предположим,
пользователь задал функцию:
(defun квадрат (x) (* x x))
==> квадрат
|
При обработке S-выражения (defun квадрат (x) (* x x))
в списке объектов будет создан атом квадрат; у этого
атома будет установлен флаг EXPR. Кроме того, будет
построен список ((x)(TIMES x x)) и ссылка на этот список
будет занесена в поле "определяющее выражение" информационной
ячейки атома "квадрат". В памяти все это займет вот
такую конфигурацию:
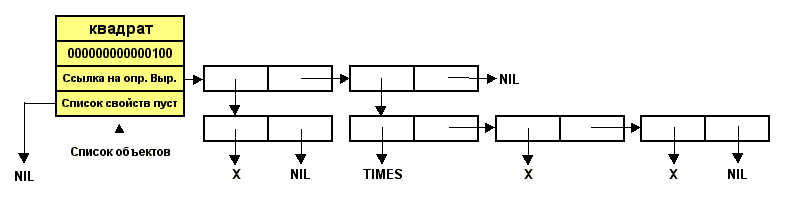
|
|
|
Внутреннее представление функции
|
Другой важнейшей внутренней структурой Лиспа помимо списка объектов
является ассоциативный
список, состоящий из пар (имя .
значение). Имя - это имя переменной, создаваемой вызовами
SET/SETQ. Значение - это произвольное S-выражение. Если,
например, пользователь выполнил команду:
(Setq A '((B C) D E))
==> ((B C) D E)
|
то в ассоциативный список будет добавлена пара (A . ((B C)
D E)) (совпадающая, разумеется, со списком (A (B C) D
E). В графической нотации это будет выглядеть так:
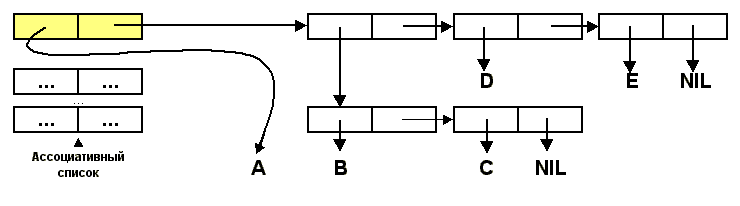
|
|
|
Вершина ассоциативного списка после вызова
(Setq A '((B C) D E))
|
Теперь читатель подготовлен к тому, чтобы понять как образуется мусор. Предположим, пользователь ввел простейшие команды
и получил ответ:
(setq a1 '(a b c))
==> (a b c)
(setq a1 1)
==> 1
|
После выполнения первой из приведенных выше команд произойдет
следующее:
- в списке объектов образуется три новых атома - a, b и c;
- в области списочной памяти образуется список (a b c);
- в ассоциативном списке образуется пара a1 . ссылка на список (a b c)
После выполнения второй команды в списке объектов возникнет атом 1 (если
его там не было), а пара a1 . ссылка на список (a b c) будет заменена парой
a1 . ссылка на атом 1. А куда же делся список
(a b c)?
Он располагается на том же месте, что и после выполнения первой команды, но теперь
недоступен, поскольку имя a1 связано с атомом 1.
Подобные структуры, которые занимают память, но недоступны, называют мусором.
Все сказанное можно проиллюстрировать рисунками:
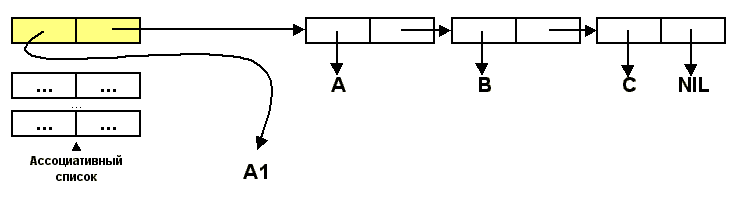
|
|
|
Результат вычисления (setq a1 '(a b c))
|
|
|
|
Результат вычисления (setq a1 1). Список (a b c) стал мусором.
|
При длительной работе мусор может занять значительную область памяти или даже всю свободную
память, что сделает дальнейшую работу невозможной.
Здесь нужно обратить внимание на одну особенность реализации системы HomeLisp: атомы и
списочные ячейки являются объектами языка реализации (Visual Basic 6.0). Те, кто знаком
с ООП-средствами языка Visual Basic, знают, что объект автоматически уничтожается, когда унитожается
последняя ссылка на этот объект. Отсюда следует, что в приведенном выше случае,
список (a b c d) будет автоматически уничтожен: уничтожение ссылки на первый
элемент вызовет уничтожение первого элемента списка (ссылки на атом a и ссылки на подсписок
(b c d)) вызовет уничтожение второго элемента (b) и т.д. Все это немного напоминает
"эффект домино".
Так может быть, никаких специальных средств для утилизации мусора придумывать и не нужно?
К сожалению, не все так просто... Использование функций rplaca и rplacd позволяет
создавать циклические списки. Циклический список невозможно распечатать (печать займет
бесконечное время) и его невозможно изобразить в скобочной или точечной нотации (по этой же причине).
Однако его можно создать и нарисовать, используя стрелки. Ниже приводится внутренняя структура линейного и циклического
списков:
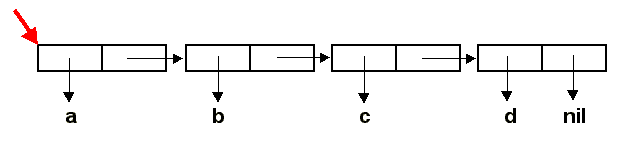
|
|
|
Внутренее строение линейного списка
|
|
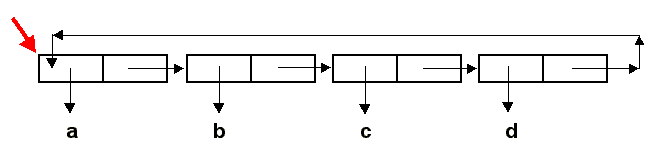
|
|
|
Внутренее строение циклического списка
|
Красной стрелка на обоих рисунках обозначена ссылка из ассоциативного списка.
Теперь ясно, что если уничтожается связь, обозначенная красной стрелкой, на верхнем рисунке,
то будет унитожена первая списковая ячейка. Это приведет к удалению ссылки на вторую ячейку.
Поскольку это единственная ссылка на вторую ячейку, то будет уничтожена и вторая ячейка и
т.д. - "косточки домино" обрушатся полностью. Все списковые ячейки будут уничтожены. Следует
обратить внимание на то, что уничтожатся только списковые ячейки (на рисунке это
прямоугольники, разделенные пополам).
Атомы a, b, c и d никуда не денутся; они останутся в списке объектов.
Если же уничтожается связь, обозначенная красной стрелкой, на нижнем рисунке,
то вообще ничего не произойдет - ведь на первую списковую ячейку имеется две
ссылки (красная стрелка и ссылка от последней списковой ячейки). Уничтожив первую ссылку
мы ничего не добьемся - вторая ссылка не позволит первой ячейке самоуничтожться. "Косточки домино"
устоят. При уничтожении ссылки на циклический список возникает мусор!
Эта ситуация демонстрируется на врезке, приводмой ниже:
(setq L '(a b c))
==> (a b c)
(setq L nil)
==> NIL
(gc)
Утилизировано ячеек: 0; атомов: 0.
(setq L '(a b c))
==> (a b c)
(setq L (rplacd (cdr (cdr L)) L))
==> (c a b c a b c a b c a b c a b c a b c a b c a b c a b
c a b c a b c a b c a b c a b c a b c a b c a b c a b
c a b c a b c a b c a b c a b c a b c a b c a b c a b
c a b c a b c . ...)
(setq L nil)
==> NIL
(gc)
Утилизировано ячеек: 3; атомов: 0.
|
Здесь создается линейный список (a b c), и
присваивается переменой L. Потом переменной L
присваивается значение Nil, и список (a b c)
удаляется из памяти автоматически, - вызов функции
GC не фиксирует наличие мусора. Затем линейный
список (a b c) вновь создается и с помощью функции
rplacd "закольцовывается". Видно, как HomeLisp
пытается его распечатать. А затем переменной L
присваивается значение Nil. Будь список линейным, он
бы при этом уничтожился автоматически. Но, поскольку список
циклический, он остается в памяти в виде мусора. И видно,
что сборщик мусора нашел три списковые ячейки.
Мусор может образоваться и в списке объектов. Убедиться в этом совсем просто.
Предположим, пользователь ввел команду и получил соответствующий ответ:
(+ 111 222 333 444)
==> 1110
|
Если атомы 111, 222, 333, 444 и 1110 (все или некоторые) не существовали,
они будут созданы. Но ни одна из существующих списочных структур не ссылается на эти
"свежесозданные" атомы. Таким образом, следует признать, что такие атомы хотя и доступны, но
бесполезны - их можно удалять из списка объектов. Может показаться, что таких
бесполезных атомов образуется немного. Вычислим, однако, число 100!.
(для этого есть функция fact, входящая в библиотеку дополнительных функциий). Можно
убедиться, что после вычисления образуется 194 новых атома! Это происходит потому, что
вычисление арифметических выражений в Лиспе принципиально отличается от вычисления в
традиционных языках (Бэйсик, Си, Паскаль).
Чтобы понять суть отличий, рассмотрим простейший оператор присвоения в традиционном
языке программирования (например, в Бэйсике):
в предположении, что целая переменная x имела до выполнения этого оператора значение,
скажем, 5. После выполнения этого оператора переменная x получит значение
6, которое будет храниться в двухбайтовой ячейке памяти, соответствующей переменной
x. Старое значение переменной x будет заменено новым.
Аналогичный оператор в Лиспе запишется так:
Выполнение его пройдет в два этапа: сначала вычисляется (+ x 1); при этом результат
будет равен атому 6. Этот атом занесется в список объектов. На втором этапе d-указатель
ячейки ассоциативного списка, хранящей переменную x будет исправлен. Теперь этот
указатель будет указывать на атом 6. Но атом 5 останется в списке объектов, -
его оттуда никто не удалял. Если какое-либо из загруженных в память S-выражений ссылается
на атом 5, то этот атом и не нужно удалять. А вот если ни одно из загруженных
S-выражений не ссылается на атом 5, то этот атом становится мусором.
Возвращаясь к расчету 100!, легко видеть, что любой алгоритм рассчета факториала
(рекурсивный или итерационный) будет вынужден вычислять 2, 3, ... 100, а также 2!, 3!, ... 100! и результаты всех
этих промежуточных вычислений (атомы 1, 2, 3 ... и 2!, 3!, ... 100!) попадут в список объектов!
Если какие-либо из этих атомов не нужны никаким S-выражениям, то их можно безболезненно
удалить из системы.
Осталось сказать несколько слов о том, как реализована уборка мусора. Реализация
функции GC в системе HomeLisp выполнена несколько проще, чем описано
в книге Лаврова и Силагадзе. Выполнение проходит в два этапа: сначала отмечаются все списочные
ячейки и информационные ячейки атомов, входящие в какое-либо S-выражение, находящееся в памяти.
Доступ к заголовкам S-выражений осуществляется через ассоциативный список и список объектов.
Затем просматриваются все созданные списочные ячейки и информационные ячейки атомов
и удаляются те из них, которые непомечены. Для отметки списочных и информационных ячеек,
предусмотрены соответствующие флаги. Упрощение по сравнению с реализацией Лаврова и Силагадзе
заключается в том, что, во-первых, процедура разметки сделана рекурсивной, и, во-вторых
освобождаемую память не требуется собирать в пул свободной памяти (это делает менеджер
памяти языка реализации - Visual Basic).
|
|
|
|
|
|
|
|
Функция GENSYM (реализованная только в 13-й редакции ядра)
создает символ (атом), которого еще гарантировано нет в
текущем состоянии Лисп-машины. Функция принимает один необязательный параметр
строкового типа (префикс имени символа). Если параметр задан ("PPPP"), то будет построен символ
PPPPnnn; если параметр опущен, то строится символ Gnnn. В обоих случаях
nnn - число, обеспечивающее уникальность созданного символа.
Все сказанное иллюстрируется примерами:
(gensym)
==> g1
(gensym "q")
==> q2
(gensym "qwerty")
==> qwerty3
(gensym)
==> g4
(setq g5 2)
==> 2
Создана глобальная переменная g5
(gensym)
==> g6
|
Логика работы функции GENSYM вполне понятна - когда пользователь создал
глобальную переменную g5, следующий вызов функции GENSYM вернул
символ g6.
|
|
|
|
|
|
|
|
Функция GETD принимает единственный аргумент - имя функции и возвращает тело
этой функции. Если запрашивается тело функции, отсутствующей в системе, то
функция GETD возвращает Nil:
(getd fact)
==> (EXPR (x)(COND
((MINUSP x) ERRSTATE)
((EQ x 0) 1)
((EQ x 1) 1)
(T (TIMES x (fact (DIFFERENCE x 1))))))
(getd чушь)
==> NIL
|
На приведенной выше врезке тело функции fact для удобства отформатировано.
Следует обратить внимание
на то, что тело функции возвращается c флагом типа функции (EXPR/FEXPR/MACRO).
Главное назначение функции
GETD состоит не в просмотре тел функций (проще это сделать, просматривая список
объектов), а в модификации тела функции во время выполнения. Поскольку тело функции представляет
собой S-выражение, то пользователь может модифицировать его во время выполнения, что
позволяет фактически создать из одной функции другую. Чтобы занести модифицированное
тело функции "на место" служит парная функция PUTD.
|
|
|
|
|
|
|
|
Функция GETEL (отсутствующая у Лаврова и Силагадзе) принимает два аргумента. Значением первого аргумента должен быть непустой список,
а значением второго - число типа FIXED. Функция возвращает элемент списка (заданого значением первого
аргумента) с номером, равным значению второго аргумента. Если значение второго аргумента неположительно -
возбуждается состояние ошибки с соответствующей диагностикой. Если значение второго аргумента выводит
за пределы списка, заданого значением первого аргумента, то функция возвращает атом OutOfRange.
Все это продемонстрировано ниже:
(getel '(a b c) 2)
==> b
(getel '(a b (c d e f)) 3)
==> (c d e f)
(getel '(a b (c d e f)) 4)
==> OutOfRange
(getel '(a b (c d e f)) -6)
GETEL: Значение номера элемента неположительно
==> ERRSTATE
|
Функция GETEL легко может быть написана на Лиспе; реализация этой
функции, как функции типа SUBR, выполнена исключительно для эффективности.
|
|
|
|
|
|
|
|
Функция GEVAL по своему действию полностью аналогична функции EVAL. Отличие заключается
в вычислении значений переменных, входящих в S-выражение, являющееся аргументом. Если функция GEVAL
вызвана в теле PROG-конструкции с локальными переменными, и какие-либо из локальных переменных
входят в аргумент GEVAL, то в ассоциативном списке ищется одноименная переменная не входящая в список локальных.
Если такая переменная найдена - используется ее значение. Если свобдная переменная не найдена -
возбуждается состояние ошибки. Другими словами, функция GEVAL не видит локальных переменных
(вычисляется в глобальном контексте).
Более подробно поведение функции GEVAL рассматривается
в разделе, посвященному контексту вычислений.
На приведенной ниже врезке показана разница в поведении функций EVAL и GEVAL:
(setq z 11111)
==> 11111
(defun f1 (n) (prog (z) (setq z 22222) (return (eval n))))
==> f1
(f1 'z)
==> 22222
(defun f2 (n) (prog (z) (setq z 22222) (return (geval n))))
==> f2
(f2 'z)
==> 11111
(unset 'z)
==> 0
(f1 'z)
==> 22222
(f2 'z)
Символ не имеет значения (не связан).
==> ERRSTATE
|
Здесь происходит следующее: заводится глобальная переменная z и две модельные функции - f1 и
f2. В обоих функциях заводится локальная PROG-переменная z, которой присваивается значение,
отличное от значения свободной переменной z. Функция f1 использует EVAL; ей недоступно
значение глобальной переменной. Функция f2 использует GEVAL, поэтому ей доступно
значение глобальной переменной.
Если уничтожить глобальную переменную вызовом UNSET, то поведение функции f1 не изменится.
А вот функция f2 теперь не найдет глобальную переменную z; выполнение завершится ошибкой.
|
|
|
|
|
|
|
|
Функция GO принимает единственный аргумент - атом-метку. После чего управление
передается оператору, следующему за заданной меткой. Эта функция может применяться только
внутри конструкции PROG. Попытка вызвать функцию GO вне PROG порождает
ошибку. Более подробно функция GO будет рассмотрена в разделе, посвященном конструкции
PROG.
|
|
|
|
|
|
|
|
Функция-предикат GREATERP принимает два аргумента числового типа. Если значение первого
аргумента больше значения второго, то функция возвращает T, в противном случае
функция возвращает Nil.
Примеры вызова GREATERP
приводятся ниже:
(greaterp 777.0 999.0)
==> NIL
(greaterp 999.0 777.0)
==> T
(greaterp 999 777)
==> T
(greaterp 777 999)
==> NIL
|
|
|
|
|
|
|
|
|
Функция-предикат GREQP принимает два аргумента типа FIXED или FLOAT. Если значение первого
аргумента больше или равно значению второго, то функция возвращает T, в противном случае
функция возвращает Nil.
Примеры вызова GREQP
приводятся ниже:
(greqp 111 222)
==> NIL
(greqp 222 111)
==> T
(greqp 111 111)
==> T
(greqp 222 111.0)
==> T
|
Поскольку данные типа FLOAT обрабатываются с
погрешностью, проверка двух значений FLOAT на точное
равенство обычно лишена смысла. Для того, чтобы убедиться,
что два значения типа FLOAT достаточно близки,
следует вычислить модуль их разности и убедиться, что его
величина достаточно мала.
|
|
|
|
|
|
Функция GSET ведет себя аналогично функции SET, но не действует на значения локальных
PROG-переменных (работает в глобальном контексте). Если глобальной переменной, заданной значением
аргумента GSET не существует, то переменная будет создана. При вызове вне PROG-конструкции
GSET эквивалентна обычной SET. Другими словами, функция GSET
вычисляется в глобальном контексте.
Более подробно поведение функции GSET рассматривается в разделе,
посвященному контексту вычислений, а ниже приведен пример, поясняющий разницу в поведении
функций SET и GSET:
(prog (z) (set 'z 1111) (print z) (return z))
1111
==> 1111
z
Символ z не имеет значения (не связан).
==> ERRSTATE
(prog (z) (gset 'z 1111) (print z) (return z))
NIL
==> NIL
z
==> 1111
|
В первом случае вызов (set 'z 1111) присваивает значение локальной
переменной. После завершения PROG-конструкции попытка вычислить значение
глобальной переменной z вызывает ошибку. Использование GSET вместо
SET дает другой эффект: локальная переменная не получает значения, зато
создается переменная z в глобальном контексте.
|
|
|
|
|
|
|
|
Функция IF, реализованная только в 13-й редакции ядра HomeLisp и принадлежащая к классу FSUBR,
принимает два обязательных параметра и один необязательный. Все параметры должны быть формами.
Работа функции заключается в том, что
сначала вычисляется значение первого параметра. Если результат отличен от Nil,
то вычисляется второй параметр и функция возвращает результат вычисления. Если же значение
первого параметра есть Nil, то вычисляется значение третьего параметра (при его наличии)
и результат возвращается в качестве результата. Если же третий параметр не задан, а значение
первого параметра есть Nil, то функция IF вернет Nil.
Легко видеть, что программная логика вычисления IF в точности соответствует
программной логике классического оператора IF (в его краткой или полной форме)
IF (...) Then Полная форма
...
Else
...
End if
или
IF (...) Then Краткая форма
...
End if
|
без "синтаксического сахара" (Then, Else, End if). Естественно, вызовы функции IF могут
быть вложены.
Примеры:
(let ((x 111)) (if (= 0 (% x 2)) 'Четное 'Нечетное))
==> Нечетное
(let ((x 222)) (if (= 0 (% x 2)) 'Четное 'Нечетное))
==> Четное
(let ((x 333)) (if (= 0 (% x 2)) 'Четное ))
==> NIL
|
В последнем случае использована краткая форма вызова IF.
|
|
|
|
|
|
|
Функция IMPLODE, реализованная только в 13-й редакции ядра HomeLisp и принадлежащая к классу SUBR,
принимает единственный обязательный параметр - список, состоящий из атомов.
Функция "сжимает" все элементы списка и возвращает получившийся символ (атом).
Функция является в некотором смысле обратной по отношению к функции EXPLODE.
Особые атомы (&DT,&DQ, &AP, &BL и &BQ) функция при
"сжатии" заменяет на точку, двойные кавычки, апостроф, пробел
и обратный апостроф соответственно.
Примеры:
(implode '(a b c))
==> abc
(implode '(a b &bl c))
IMPLODE: Попытка внести пробел в имя атома
==> ERRSTATE
(implode '(&dq a b &bl c &dq))
==> "ab c"
(implode '(a b &dt c))
==> ab.c
|
Видно, что функция IMPLODE не позволит занести пробел в имя атома
(при условии, что этот атом - не строка).
|
|
|
|
|
|
|
|
Конструкция LAMBDA позволяет задавать безымянные функции, которые затем можно
использовать, напрмер, как функциональные аргументы. Однако у подобных функций есть один
недостаток: такие функции не могут быть рекурсивными. В самом деле, рассмотрим простую рекрсивную
функцию:
(defun f (x) (... (f ...) (f ...) ...))
Здесь видно, что функция f дважды вызывает сама себя. Если у функции нет имени,
то непонятно, как синтаксически оформить вызов самой себя.
Отмеченную проблему решает функция LABELS, реализованная только в 13-й редакции ядра HomeLisp и принадлежащая к классу FSUBR.
Эта функция обеспечивает создание вычисление локальных функций. Общая схема вызова
LABELS такова:
|
(LABELS
|
((опр_1) (опр_2) ... (опр_n))
|
|
|
(вызов_1) (вызов_2) ... (вызов_m))
|
Можно отметить, что вызов LABELS включает область определений локальных
функций (выделено на предыдущем рисунке голубым) и область вызовов. Таким образом,
один вызов LABELS позволяет создать и вызвать несколько локальных функций. При этом
вычисления в области вызова могут, в свою очередь, использовать функцию LABELS
(т.е. вызовы LABELS могут быть вложенными).
Каждое определение в области определений есть конструкция, полностью аналогичная
DEFUN, но без атома DEFUN. У такого определения функции есть имя,
но оно видимо только в пределах вызова LABELS.
Теперь можно рассмотреть примеры:
(labels ((fa (n) (if (= n 0) 1 (* n (fa (sub1 n)))))) (fa 6))
==> 720
(fa 5)
EVFUN: Не найдена функция FA
==> ERRSTATE
(defun f1 (x) (* x x x))
==> f1
(labels ((f1 (x) (* x x))
(f2 (x) (+ x 4)))
(labels ((f3 (x y) (* x y))) (+ (f1 6) (f2 7) (f3 11 22))))
==> 289
(f1 6)
==> 216
|
В первом примере задана локальная функция вычисления факториала. Следующий
вызов (fa 5) сделан исключительно для того, чтобы убедиться, что локальная функция
fa "живет" в теле LABELS.
Далее определяется обычная функция f, вычисляющая куб своего аргумента. Затем
вычисляется сложная конструкция, состоящая из двух вложенных вызовов LABELS.
В вызове верхнего уровня создаются две локальные функции f1 и f2.
Во вложенном вызове создается локальная функция f3 и все три локальные функции
используются при вычисления результата. Получается, как и положено, 6*6+7+4+11*22=289.
Последующий вызов (f1 6), что функция f1, созданная ранее, нисколько
не пострадала.
|
|
|
|
|
|
|
|
Конструкция LAMBDA позволяет задавать т.н. безымянные функции. LAMBDA не является
функцией - если посмотреть список свойств атома LAMBDA, то можно убедиться, что список
включает единственный стандартный флаг APVAL (а, скажем, у CAR в списке свойств
будет флаг SUBR). Безымянная функция представляет собой следующую конструкцию:
(LAMBDA список_формальных_параметров определяющее_выражение)
Список формальных параметров представляет собой список атомов. Определяющее выражение может быть любым
допустимым выражением, имеющим значение. Это выражение может содержать ссылки на переменные
из списка формальных параметров. Чтобы вызвать безымянную функцию, нужно написать выражение:
((LAMBDA список_формальных_параметров определяющее_выражение) список_фактических_параметров)
Вычисление такого выражения выполняется так: сначала каждому из формальных параметров присваивается
значение соответствующего ему фактического параметра. Если списки формальных и фактических параметров
имеют разную длину - фиксируется ошибка. Далее вычисляется определяющее выражение. Результат
вычисления возвращается, как результат вычисления безымянной функции. И, наконец, уничтожаются
формальные параметры. В целом безымянная функция отличается от обычной (именованной) только
наличием имени.
Вот несколько примеров:
((lambda (x) (* x x)) 6)
==> 36
((lambda (x) (* x x)) 6 7)
==> Список значений и список переменных имеют разную длину
((lambda (x) 1234) 7)
==> 1234
|
В первом примере используется безымянная функция, возводящая в квадрат значение своего единственного
аргумента. Во втором примере показана неудачная попытка вызвать безымянную функцию одного
аргумента с двумя фактическими аргументами. В третьем примере определяющее выражение не использует
аргумент - это допустимо.
Остается сказать, что название LAMBDA ведет свою историю с т.н. лямбда-исчисления,
придуманного логиком и математиком Черчем в 20-30-е годы прошлого века. Греческая буква
лямбда уже давно является символом функциональных языков.
Все сказанное выше относится к обеим редакциям ядра HomeLisp. Конструкция
LAMBDA в 13-й редакции ядра имеет важное отличие
от таковой в в 11-й редакции. Если подать на вход
Лисп-машины лямбда-выражение само по себе, то произойдет ошибка:
_ver
==> "HomeLisp Вер=1.11.2 Date=01.11.2010 Time=14:28:02"
(lambda (x y) (* x y))
Не найдена функция LAMBDA
==> ERRSTATE
|
Видно, что 11-я редакция ядра HomeLisp
воспринимает лямбда-выражение, как вызов функции, а фунции LAMBDA в системе нет.
Совсем по-другому поведет себя предыдущий пример, если выполнить его в среде
13-го ядра HomeLisp:
_ver
==> "HomeLisp Вер=1.13.1 Date=20.05.2011 Time=19:48:02"
(lambda (x y) (* x y))
==> (CLOSURE (x y) ((* x y)) NIL)
|
Видно, что в среде 13-го ядра HomeLisp
лямбда-выражение порождает новую конструкция - замыкание (CLOSURE).
Замыкания, порождаемые лямбда-выражениями, сходны с замыканиям, порождаемыми
вызовами DEFUN в теле LET. Ниже будут рассмотрены лексические замыкания,
реализуемые с помощью LAMBDA-конструкции.
Замыкание - это агрегат, состоящий из определения функции и зафиксированных связей
свободных переменных. Причем, доступ к зафиксированным связям свободных переменных должна
иметь только эта функция (принцип инкапсуляции).
Одним из способом создания замыкания является вызов DEFUN/SEXPR
в теле LET-конструкции. Связи свободных переменных при этом сохраняются в специальном
поле информационной ячейки атома-имени функции. Другой способ создания замыкания состоит в
вычислении лямбда-выражения (без задания значений праметров). Результат вычисления
лямбда-выражения в HomeLisp есть список, состоящий из:
специального атома CLOSURE;
списка параметров исходного лямбда-выражения;
тела исходного лямбда-выражения;
списка значений лексических переменных контекста вызова.
Таким образом, чтобы создать замыкание из лямбда-выражения, нужно вычислить это выражение
без задания параметров в подходящем лексическом контексте и сохранить результат вычисления
как значение какой-либо переменной. Обратиться к созданному таким образом замыканию можно
с помощью вызова FUNCALL. Ниже приводится пример генератора - функции,
возвращающей при каждом вызове очередной член некоторой последовательности. В нашем случае
генератор возвращает последовательные целые числа.
(let ((c 0)) (setq counter (lambda nil (setq c (add1 c)))))
==> (CLOSURE NIL ((SETQ c (ADD1 c))) ((c 0)))
Создана глобальная переменная counter
(funcall counter)
==> 1
(funcall counter)
==> 2
(funcall counter)
==> 3
counter
==> (CLOSURE NIL ((SETQ c (ADD1 c))) ((c 3)))
|
Из приведенного примера хорошо видно, как работает генератор. При следующем
вызове (посредством FUNCALL) генератор вернет 4 и значение
внутренней локальной переменной станет равно четырем.
Может возникнуть вопрос: а что будет, если создать список со структурой, идентичной
приведенному выше замыканию, и обратиться к этому списку с помощью FUNCALL?
Ниже показан исход такого эксперимента:
(setq z '(CLOSURE NIL ((SETQ c (ADD1 c))) ((c 0))))
==> (CLOSURE NIL ((SETQ c (ADD1 c))) ((c 0)))
Создана глобальная переменная z
(funcall z)
Apply_: Недопустимое употребление CLOSURE
==> ERRSTATE
|
В HomeLisp встроен механизм защиты, запрещающий "конструировать" замыкания,
как списки и модифицировать существующие замыкания. В других системах (например,
в XLisp) пользователь вообще лишен
возможности увидеть структуру замыкания. Поскольку HomeLisp предназначается
для обучения Лиспу, разработчик принял решение "показывать" замыкания. Однако
возможность конструировать замыкания, как списки или модифицировать существующие
замыкания нарушило бы принцип инкапсуляции данных. Поэтому попытка модифицировать
значение "замкнутой" переменной вызовет ошибку:
(let ((c 0)) (setq counter (lambda nil (setq c (add1 c)))))
==> (CLOSURE NIL ((SETQ c (ADD1 c))) ((c 0)))
Создана глобальная переменная counter
(funcall counter)
==> 1
(rplaca (cdar (cadddr counter)) 6)
RPLACA: попытка модификации защищенной структуры
==> ERRSTATE
(funcall counter)
==> 2
|
Еще одним отличием LAMBDA-конструкции 13-й редакции ядра является то, что
в новой редакции тело LAMBDA-конструкции может включать несколько последовательно
вычисляемых S-выражений. Результатом вычисления LAMBDA-конструкции будет результат
вычисления почледнего S-выражения.
|
|
|
|
|
|
|
|
Функция LEFTSHIFT принимает два аргумента. Первый аргумент должен иметь тип BITS,
т.е. быть 32-х битовой логической шкалой. Второй аргумент должен иметь тип FIXED.
Функция возвращает значение первого аргумента, сдвинутое влево или вправо на количество
разрядов, равное модулю значения второго аргумента. При этом, если значение второго аргумента
положительно, сдвиг происходит влево. При отрицательном значении второго аргумента сдвиг
происходит вправо. При сдвиге влево освободившиеся разряды заполняются нулями. При сдвиге
вправо в освободившиеся разряды заносится самый старший разряд.
Примеры вызова LEFTSHIFT приводятся ниже:
(leftshift &h77 3)
==> &H3B8
(leftshift &h77 -3)
==> &HE
(leftshift &hEEEEEEEE -3)
==> &HFDDDDDDD
|
|
|
|
|
|
|
|
|
Функция-предикат LESSP принимает два аргумента числового типа и возвращает T
если значение первого аргумента меньше значения второго. В противном случае возвращается
Nil. LESSP допускает аргументы типа FIXED и FLOAT.
Примеры вызова LESSP
приводятся ниже:
(lessp 1 2)
==> T
(lessp 2 1)
==> NIL
(lessp 2.0 1)
==> NIL
(lessp 2.0 1.0)
==> NIL
(lessp 1.0 2.0)
==> T
|
|
|
|
|
|
|
|
|
Функции LET/LET* (типа FSUBR), реализованные только в 13-й редакции
ядра, предназначены для управления лексическим контекстом (создания локальных переменных).
Функции имеют следующую синтаксическую форму:
(LET/LET* (список переменых) форма1 форма2 … формаn)
Список переменных является списком, состоящим из духэлементных списков (имя форма_вычисления_значения).
Функция вычисляется следующим образом: создается новый лексический контекст и в него заносятся
переменые из списка переменных, значения которых вычисляются.
Если LET вычисляется в непустом лексическом контексте, переменные из списка переменных
заносятся в начало нового контекста.
Далее последовательно вычисляются формы форма1, форма2 … формаn.
Вычисления происходят в созданном лексическом контексте.
Результат вычисления последней формы возвращается как результат LET, а лексический
контекст вычислений восстанавливается.
Функция LET* отличается от LET только тем, что при вычислении значения очередной
переменной из списка доступны значения уже ранее вычисленных переменных (последовательное вычисление).
При вычислении LET переменные вычисляются "сразу все" - значения уже вычисленных
переменных не доступны при вычислении последующих. В остальном функции не различаются.
Примеры:
(let ((a 111) (b 222)) (printline a) (printline b))
111
222
==> 222
a
Assoc: Символ a не имеет значения (не связан).
==> ERRSTATE
b
Assoc: Символ b не имеет значения (не связан).
==> ERRSTATE
|
Здесь созданы две локальные переменные, доступные в теле LET. Попытка
получения этих переменных вне контекста их определения вызывает ошибку.
Еще пример:
(let ((a 111) (b (* a 222))) (printline a) (printline b))
Внутри LET: Символ a не имеет значения (не связан).
==> ERRSTATE
(let* ((a 111) (b (* a 222))) (printline a) (printline b))
111
24642
==> 24642
|
Первый вызов завершается ошибкой, поскольку при вычислении локальной
переменной b требуется значение переменной a, а оно еще не доступно.
Если же вместо LET использовать LET*, то значение переменной
a будет доступно и вычисления завершаются предсказуемым результатом.
Достаточно интересно то, что если создать глобальную переменную a,
то пример, который выше завершился ошибкой, отработает нормально:
(setq a 333)
==> 333
Создана глобальная переменная a
(let ((a 111) (b (* a 222))) (printline a) (printline b))
111
73926
==> 73926
|
Понятно, почему это происходит: при вычислении формы (* a 222) будет использовано
не значение локальной переменной (оно еще не доступно), а значение
глобальной переменной a.
Вызовы LET могут быть вложенными. Вот пример вложенных вызовов LET:
(let ((a 111) (b 222))
(printline (context))
(let ((a 333) (c (* 2 a)))
(printline (context))
'ok
)
)
(((b 222) (a 111)) NIL)
(((c 222) (a 333) (b 222) (a 111)) NIL)
==> ok
|
При первом вызове создается контекст из двух переменных a и b со значениями 111 и 222
соответственно. Этот контекст печатается. Далее вызывается внутренняя LET и к текщему
контексту в начало добавляется переменная а со значением 333 и переменная с со значением,
равным 2*a, но берется значение из внешего LET (оно доступно). После чего снова печатается
текущий контекст. Кстати, все сказанное означает, что во внутреннем LET значением a будет
333, а не 111 (при вычислении значений контекст просматривается от начала к концу и сначала
попадется значение 333.
Функции LET и LET* позволяют строить лексические замыкания, рассматриваемые ниже.
Лексическое замыкание (или просто замыкание) это определение функции с зафиксированными связями
свободных переменных. Замыкание можно построить, если вызвать функцию DEFUN или SEXPR
в контексте, созданным вызовом LET:
(let ((c 0)) (defun next nil (setq c (add1 c))))
==> next
(next)
==> 1
(next)
==> 2
(context 'next)
==> ((c 2))
|
Здесь у функции next переменная c является свободной. Если бы определение
функции next вводилось на верхнем уровне и отсутствовала бы глобальная переменная
c, то функция была бесполезной: при вызове возникала бы ошибка при вычислении
(add1 c). В приведенном же выше случае переменная c входит в лексический
контекст, который запоминается в предназначенном для этого поле информационной ячейки
атома next. Каждый вызов next увеличивает значение докальной переменной
с на единицу и возвращает значение этой переменной. Подобная конструкция называется
генератором. Созданный выше генератор позволяет только "шагать вперед" (нет возможности
сбросить значение внутренней переменной). Чтобы обеспечить такую возможность, нужно определить
функцию сброса в том же контексте, что и функцию next:
(let ((c 0))
(defun next nil (setq c (add1 c)))
(defun reset nil (setq c 0))
)
==> reset
(next)
==> 1
(next)
==> 2
(next)
==> 3
(reset)
==> 0
(next)
==> 1
(eql (context 'next) (context 'reset))
==> T
|
Здесь создано два замыкания - next и reset, причем, лексический
контекст у них общий. Это приводит к тому, что обнуление переменной
c при вызове reset заставляет next считать с нуля.
|
|
|
|
|
|
|
|
Функция LIST принимает произвольное число аргументов, строит из них список и возвращает
его в качестве значения. Поскольку функция принадлежит к типу SUBR, ее аргументы вычисляются.
Для предотвращения вычисления следует использовать квотирование.
Примеры вызова LIST
приводятся ниже:
(list 1 2 3)
==> (1 2 3)
(list 1 2 (3 4))
==> Не найдена функция 3
(list 1 2 '(3 4))
==> (1 2 (3 4))
|
Во втором примере возникает ошибка, поскольку предпринимается попытка вычислить список
(3 4). Чтобы предотвратить нежелательное вычисление в третьем примере применено
квотирование.
|
|
|
|
|
|
|
|
Функция LOGAND принимает произвольное количество аргументов типа BITS и возвращает их
логическое произведение. Логическое произведение - это битовая операция AND, которой
соответствует таблица истиности:
| X |
Y |
X AND Y |
| 0 |
0 |
0 |
| 1 |
0 |
0 |
| 0 |
1 |
0 |
| 1 |
1 |
1 |
Примеры вызова LOGAND
приводятся ниже:
(logand &H11 &H22)
==> &H0
(logand &H7734 &HFF00)
==> &H7700
(leftshift (logand &H7734 &HFF00) -8)
==> &H77
|
Функция применяется для выделения одного или более битов в шкале.
|
|
|
|
|
|
|
|
Функция LOGOR принимает произвольное количество аргументов типа BITS и возвращает их
логическую сумму. Логическая сумма - это битовая операция OR, которой
соответствует таблица истиности:
| X |
Y |
X OR Y |
| 0 |
0 |
0 |
| 1 |
0 |
1 |
| 0 |
1 |
1 |
| 1 |
1 |
1 |
Примеры вызова LOGOR
приводятся ниже:
(logor &H11 &H22)
==> &H33
(logor &H7734 &HFF00)
==> &HFF34
(leftshift (logor &H7734 &HFF00) -8)
==> &HFF
|
Функция применяется для поднятия (установки) одного или более битов в шкале.
|
|
|
|
|
|
|
|
Функция LOGXOR принимает произвольное количество аргументов типа BITS и
возвращает их побитовое отрицание равнозначности - результат
битовой операции XOR, которой
соответствует таблица истиности:
| X |
Y |
X XOR Y |
| 0 |
0 |
0 |
| 1 |
0 |
1 |
| 0 |
1 |
1 |
| 1 |
1 |
0 |
Примеры вызова LOGXOR
приводятся ниже:
(logxor &H11 &H22)
==> &H33
(logxor &H7734 &HFF00)
==> &H8834
(leftshift (logxor &H6634 &HFF00) 8)
==> &H993400
|
|
|
|
|
|
|
|
|
Фунция LOOP (типа FSUBR) отсутствует в реализации Лаврова и Силагадзе. В HomeLisp она
реализована только в 13-м ядре. Это простейшая функция организации циклов - она организует
бесконечный цикл (тело которого может составлять из произвольного числа форм).
Цикл прерывается вызовом RETURN. Контроль числа повторений и выход из цикла -
обязанность программиста. Пример:
(let ((i 0))
(loop (setq i (add1 i))
(printline i)
(if (>= i 23) (return 'ok) nil)
)
)
1
2
3
…
22
23
==> ok
|
|
|
|
|
|
|
|
|
Функция MACROEXPAND предназначена для генерация промежуточного S-выражения,
являющегося результатом макрорасширения (первого этапа выполнения) функции
типа MACRO. Такие функции вычисляются в два этапа: на первом этапе строится
S-выражение, которое вычисляется на втором этапе (передается на вход EVAL).
Функция MACROEXPAND, позволяющая увидеть это промежуточное S-выражение,
ожидает на входе список переменной длины, первым элементом
которого является атом - имя тестируемой функции типа MACRO, а последующими элементами -
параметры тестируемой функции.
Если, например, есть макро-функция MF, требующая
на входе список из двух элементов, то, чтобы увидеть промежуточное S-выражение, возникающее
при вызове (MF a1 a2), следует задать (macroexpand MF a1 a2).
Рассмотрим (следуя замечательному двухтомнику Э. Хювенен и И. Сеппянен [6]),
следующую макро-функцию:
(smacro setqq
(lambda
(x y)
(list 'setq x (list 'quote y))
)
)
|
Эта функция очень похожа на встроенную функцию setq, но, посколько
аргументы макро не вычисляются, она предполагает обращение без квотирования
второго аргумента:
(setqq a (1 2 3)):
(setqq x (1 2 3))
==> (1 2 3)
x
==> (1 2 3)
|
Чтобы увидеть результат первого этапа вычисления, следует вызвать функцию
macroexpand:
(macroexpand setqq x (1 2 3))
==> (SETQ x (QUOTE (1 2 3)))
|
|
|
|
|
|
|
|
|
Функция MAX в HomeLisp принимает произвольное число аргументов типа
FIXED или FLOAT и возвращает максимальное значение из значений
всех аргументов. Если все аргументы имеют тип FIXED, то и результат
будет иметь тип FIXED. Если среди аргументов есть хоть один типа
FLOAT, то и результат будет иметь тип FLOAT. Все сказанное
можно проиллюстрировать следующим:
(max 1 2 34 88 4 5)
==> 88
(proplist (max 1 2 34 88 4 5))
==> (FIXED)
(max 1 2 34 88 4 5.0)
==> 88.0
(proplist (max 1 2 34 88 4 5.0))
==> (FLOAT)
|
|
|
|
|
|
|
|
|
Функция MIN в HomeLisp принимает произвольное число аргументов типа
FIXED или FLOAT и возвращает минимальное значение из значений
всех аргументов. Если все аргументы имеют тип FIXED, то и результат
будет иметь тип FIXED. Если среди аргументов есть хоть один типа
FLOAT, то и результат будет иметь тип FLOAT. Все сказанное
можно проиллюстрировать следующим:
(min 88 2 34 1 4 5)
==> 1
(proplist (min 88 2 34 1 4 5))
==> (FIXED)
(min 88 2 34 1 4 5.0)
==> 1.0
(proplist (min 88 2 34 1 4 5.0))
==> (FLOAT)
|
|
|
|
|
|
|
|
|
Функция MINUS ожидает ровно один аргумент типа FIXED или FLOAT
и возвращает значение этого аргумента с противоположным знаком. Тип результата
совпадает с типом аргумента. Примеры приводятся ниже.
(minus 6)
==> -6
(proplist (minus 6))
==> (FIXED)
(minus 5.0)
==> -5.0
(proplist (minus 5.0))
==> (FLOAT)
|
|
|
|
|
|
|
|
|
Функция-предикат MINUSP ожидает ровно один аргумент типа FIXED или FLOAT
и возвращает T, если значение этого аргумента отрицательно. В противном случае
функция возвращает Nil.
Примеры приводятся ниже.
(minusp 6)
==> Nil
(minusp 0)
==> Nil
(minusp -5)
==> T
(minusp -5.0)
==> T
|
|
|
|
|
|
|
|
|
Конструкция
NLAMBDA
(реализованная только в 13-й
редакции ядра), порождает анонимную функцию, но отличается от конструкции LAMBDA )
двумя моментами:
аргументы NLAMBDA не вычисляются;
NLAMBDA не порождает замыканий.
((nlambda (x y) (list x y)) (1 2 3) (4 5 6))
==> ((1 2 3) (4 5 6))
(nlambda (x y) (list x y))
EVFUN: Не найдена функция NLAMBDA
==> ERRSTATE
(lambda (x y) (list x y))
==> (CLOSURE (x y) ((LIST x y)) NIL)
|
Первый запуск показыает, что NLAMBDA задает анонимную функцию
с невычисляемыми при вызове аргументами. Второй вызов, показывает,
что NLAMBDA не порождает замыканий (в отличие от LAMBDA).
|
|
|
|
|
|
|
|
Две функции NOT и NULL выполняют одно и то же: если их единственный
аргумент есть Nil, функции возвращают T; в противном случае возвращается
Nil:
(not 6)
==> Nil
(not Nil)
==> T
(Null 'a)
==> Nil
(Null Nil)
==> T
|
|
|
|
|
|
|
|
|
Функция-предикат NUMBERP проверяет, является значение ее единственного аргумента
числом (FIXED или FLOAT); в этом случае возвращается T. В противном
случае возвращается Nil:
(numberp 111)
==> T
(numberp 'a)
==> Nil
(numberp (+ 6 7))
==> T
|
В последнем примере сначала будет вычислено выражение (+ 6 7) и получен
результат 13. Далее будет вычисляться выражение (numberp 13),
значение которого, естественно равно T.
|
|
|
|
|
|
|
|
Функция-предикат ONEP проверяет, является значение ее единственного аргумента
типа FIXED атомом 1; в этом случае возвращается T. В противном
случае возвращается Nil. При попытке обратиться к предикату с аргументом,
имеющим тип, отличный от FIXED, возникает ошибка. Вот примеры:
(onep 1)
==> T
(onep 2)
==> Nil
(onep 1.0)
==> Аргумент ONEP не число FIXED
(onep (+ 1 0))
==> T
|
В последнем примере сначала будет вычислено выражение (+ 1 0) и получен
результат 1. Далее будет вычисляться выражение (onep 1),
значение которого равно T.
|
|
|
|
|
|
|
|
Функция OR класса FSUBR принимает произвольное число аргументов.
В процессе вычисления первый же
же аргумент, имеющий значение, отличное от Nil,
вызывает прекращение вычисления, и возвращается в качестве значения функции. Если значение всех аргументов
функции равно Nil, то функция принимает значение Nil.
Примеры:
(OR 1 2 3)
==> 1
(or (CAR '(1)) (/ 3 0))
==> 1
|
Обратите внимание, во втором примере аргумент (/ 3 0) даже не вычислялся (в противном случае
возникла бы ошибка "деление на нуль"). Это происходит вследствие того, что OR - функция
класса FSUBR. Ее аргументы не вычисляются (точнее вычисление происходит не перед,
а после вызова в теле функции от первого к последнему). Второй аргумент после вычисления
дает 1, и вычисление прекращается. Если заменить CAR
на CDR, то возникнет ошибка "деление на нуль".
|
|
|
|
|
|
|
|
Функция PARSE, отсутствующая у Лаврова и Силагадзе, принимает единственный аргумент
типа STRING, содержащий алгебраическое выражение в естественной нотации, а возвращет
это же выражение, разбитое на лексемы (токены).
Круглые скобки становятся структурными скобками результирующего S-выражения.
Лексемами являются символические имена переменых,
числовые константы и знаки алгебраических операций:
|
Знак операция
|
Выполняемое действие
|
|
+ (plus)
|
Алгебраическое сложение
|
|
- (difference)
|
Алгебраическое вычитание
|
|
* (times)
|
Умножение
|
|
/ (divide)
|
Деление с плавающей точкой
|
|
\ (quotient)
|
Целочисленное деление
|
|
% (quotient)
|
Остаток от деления
|
|
^ (expt)
|
Возведение в степень
|
|
> (greaterp)
|
Cравнение (больше)
|
|
< (lessp)
|
Cравнение (меньше)
|
|
>= (greqp)
|
Cравнение (больше или равно)
|
|
<= (leeqp)
|
Cравнение (меньше или равно)
|
|
<> (neqp)
|
Cравнение (не равно)
|
Как видно из приведенной выше таблицы, в качестве знаков операций можно применять
лисповские обозначения функций (plus, difference, times и т.д.). Однако в этом случае
знак операции должен быть окружен пробелами (в противном случае произойдет "склеивание"
знака операции с операндами).
Рассмотрим примеры:
(parse "1+3")
==> (1 + 3)
(parse "(a+b)/(a-b)")
==> ((a + b) / (a - b))
(parse "(a+b)\(a-b)")
==> ((a + b) \ (a - b))
(parse "(a+b)%(a-b)")
==> ((a + b) % (a - b))
(parse "a - c ^ 2")
==> (a - c ^ 2)
(parse "(a plus (d difference e)")
Не сбалансированы скобки во входном выражении
==> ERRSTATE
(parse "(a plus (d difference e))")
==> ((a PLUS (d DIFFERENCE e)))
|
Как можно отметить, функция PARSE
проводит контроль баланса скобок во входном выражении. При неверной скобочной
структуре функция завершается аварийно и выводится соответствующее сообщение.
Если приглядеться к приведенным выше примерам, то легко
заметить, что функция PARSE просто преобразует алгебраическое выражение из
строковой формы в инфиксную форму. Инфиксной называется форма записи
алгебраического выражения, при которой знак операции располагается между операндами.
Однако результат функции PARSE нельзя непосредственно передать интерпретатору Лиспа.
Дело в том, что Лисп использует не инфиксную, а префиксную форму (знак операции предшествует операндам).
Пусть читатель сравнит инфиксную форму (после PARSE) (a + b) и
правильную Лисповскую префиксную форму (+ a b).
Для перевода выражения из инфиксной формы в префиксную служит функция inf2pref,
входящая в библиотеку дополнительных функций.
|
|
|
|
|
|
|
|
Функция PLUS,(вместо PLUS можно писать +) вычисляет сумму значений своих аргументов, которых может быть произвольное
количество. Тип аргументов должен быть FIXED или FLOAT. При этом, если среди аргументов
есть хотя бы один аргумент типа FLOAT, то и результат будет иметь тип FLOAT.
Рассмотрим примеры:
(plus 1 3 5 7)
==> 16
(+ 1 2 3)
==> 6
(+ 1 2.0 3)
==> 6.0
|
|
|
|
|
|
|
|
|
Функция PRINT выводит значение своего единственного аргумента в область вывода.
Функция выводит данные сплошным потоком символов - следующий вызов функции PRINT
выводит свои данные вплотную к результатам предыдущего вызова функции PRINT.
Для перехода на новую строку служит функция TERPRI.
Данные типа STRING выводится с объемлющими двойными кавычками:
(print 'a)
a
==> a
(print (+ 7 8))
15
==> 15
(print "проба пера")
"проба пера"
==> "проба пера"
|
Пусть читатель обратит внимание на то, что помимо печати значения своего аргумента,
функция возвращает его в качестве результата (каждая функция должна возвращать какой-нибудь
результат!)
Функция PRINTLINE (отсутствующая у Лаврова и Силагадзе) полностью аналогична функции
PRINT, описанной выше, но вслед за выводимим значением выполняется перевод строки.
|
|
|
|
|
|
|
|
Функции PRINTS и PRINTSLINE отличаются от функций PRINT и PRINTLINE
только тем, что строки печатаются без объемлющих кавычек.
(print "a")
"a"
==> "a"
(prints "a")
a
==> "a"
(prints 56)
56
==> 56
|
Следует обратить внимание, что хотя функции PRINTS/PRINTSLINE печатают значение
своего аргумента-строки без кавычек, результат функции все равно печатается с кавычками.
Если аргумент функции PRINTS/PRINTSLINE не имеет типа STRING, действие
функций полностью аналогично действию функции PRINT/PRINTLINE, описанных выше.
|
|
|
|
|
|
|
|
Функция PROG введена в Лисп с целью обеспечить в декларативном функциональном языке возможности
императивного программирования. Общая схема конструкции PROG такова:
(PROG (список локальных переменных)
[метка] Оператор
[метка] Оператор
[метка] Оператор
... ...
)
|
Список локальных переменных представляет собой одноуровневый список атомов
(например, (a b c)). Метка - это произвольный (но уникальный в пределах PROG-конструкции
атом. То, что на приведенной выше врезке, слово "метка" заключено в кавычки, означает, что
метка - объект необязательный. Она может отсутствовать. Оператор - это вызов произвольной функции,
в том числе и функции PROG.
Опишем, как происходит вычисление PROG.
Вычисление начинается с того, что для каждого атома из списка локальных переменных создается
одноименная переменная со значением nil. Если, например, список локальных переменных
имеет вид (a b c), то при входе функцию PROG выполняются действия, эквивалентные
последовательному вычислению S-выражений:
(setq a nil)
(setq b nil)
(setq c nil)
|
Далее начинается последовательное вычисление операторов (каждый оператор - это S-выражение).
Метки при этом просто пропускаются. Среди операторов, однако, может встретиться S-выражение
(GO метка). Фактически GO - это функция с единственным аргументом - атомом,
вызов которой допустим только в теле PROG (попытка вызвать GO вне тела PROG
приводит к ошибке). Смысл вызова GO заключается в том, что следующим после GO выполняющимся оператором,
будет оператор, имеющий метку, которая является аргументом GO. Будем называть это действие
"переходом на метку". Легко видеть, что GO - это
аналог оператора GoTo, который, несмотря на яростные нападки "правоверных", имеется во
всех нормальных языках программирования. Разумеется, переход на несуществующую метку вызывает
ошибку.
Имеется еще одна функция, вызов которой допустим только в теле PROG - это функция
RETURN. Функция имеет единственный аргумент, значение которого возвращается в качестве
результата вычисления функции PROG. Можно сказать, что вызов RETURN приводит
к прекращению вычисления PROG и возврату в качестве результата PROG значения
своего аргумента.
Если вся последовательность операторов вычислена (***), то вычисление PROG завершается, а
в качестве результата возвращается Nil.
Рассмотрим примеры. Выведем значения последовательных нечетных чисел и подсчитаем их сумму.
(defun sumOdd (x) (prog (i s n)
(setq s 0)
(setq i 1)
L (setq n (- (* 2 i) 1))
(setq s (+ s n))
(print n)
(terpri)
(setq i (+ i 1))
(cond ((greaterp i x) (return s)))
(go L)
)
)
(sumOdd 6)
1
3
5
7
9
11
==> 36
|
Читатель легко увидит в этой программе цикл, образованный с помощью
COND и GO.
Следует отметить, что метки локальны в теле
PROG. Если имеются две вложенные PROG-функции, имеющие одноименную
метку, то при вызове функции GO с этой меткой в качестве аргумента во внутренней
функции, переход будет осуществлен тоже на метку внутренней функции PROG.
Вот пример на эту тему:
(prog nil
A (print 'Начало)
(terpri)
(prog nil
(setq x 1)
A (print x)
(terpri)
(setq x (+ 1 x))
(cond ((lessp x 10) (go A)))
)
)
Начало
1
2
3
4
5
6
7
8
9
==> NIL
|
В приведенном выше примере переход осуществляется на внутреннюю, а не на внешнюю
метку A. Кроме этого, пусть читатель обратит внимание, что резуьтат вычисления
всей конструкции равен Nil. Так получилось, поскольку не использовалась функция
RETURN. В этом случае функция всегда возвращает Nil.
Следует обратить внимание еще один момент: обе функции предыдущего
примера не содержат списка локальных переменных - список локальных переменных
пуст, а пустой список по определению есть Nil.
Переменные, входящие в список локальных переменных, называют также связанными переменными.
Возникает вопрос: а что произойдет, если при вызове PROG уже существует переменная,
одноименная с переменной, входящей в список связанных переменных? В частности, если значение
такой переменой изменено в теле PROG, каково будет значение переменной
после выхода из PROG. Ответ звучит так: значение связанной переменной после выхода
из функции PROG всегда будет тем же самым, что и при входе в PROG.
Связанные переменные, таким образом, можно как угодно менять в теле PROG. Вот
пример, подтверждающий сказанное:
(setq x 111)
==> 111
(prog (x)
(setq x -777)
(print 'x=)
(print x)
(terpri)
)
x=-777
==> Nil
x
==> 111
|
В приведенном выше примере переменная x связанная. Хотя ее значение в теле PROG
изменено, при выходе значение x остается прежним. Ну, а если связанная переменная до
вызова PROG не существовала, то после вызова она и не появится:
проба
==> Символ "проба" не имеет значения (не связан).
(prog (проба)
(setq проба -777)
(print 'проба=)
(print проба)
(terpri)
)
проба=-777
==> NIL
проба
==> Символ "проба" не имеет значения (не связан).
|
Переменная проба до вызова PROG не существовала. Эта переменная
связана в функции PROG. В процессе выполнения функции PROG
переменная проба получает значение, но после выхода из PROG
переменная уничтожается (атом проба снова не имеет значения).
А вот переменные, не входящие в список связанных, называются свободными. Если
в теле функции PROG значение свободной переменной изменено, то при выходе
из функции PROG это значение сохранится. Рассмотрим в подтверждение этому
уже приведенный выше пример, но исключим x из списка связанных переменных.
Результат будет уже другим:
(setq x 111)
==> 111
(prog nil
(setq x -777)
(print 'x=)
(print x)
(terpri)
)
x=-777
==> Nil
x
==> -777
|
Поведение связанных переменных функции PROG во многом напоминает поведение
параметров функций. Параметры функции тоже являются связанными переменными.
Единственная разница заключается в том, что параметры при входе получают значения
соответствующих S-выражений из списка фактических параметров, а переменные,
связанные в теле функции PROG, получают значения Nil.
|
|
|
|
|
|
|
|
Функции PROG1, PROG2 и PROGN отсутствуют у Лаврова и Силагадзе и
реализованы только в 13-й редакции ядра. Все функции имеют
тип FSUBR.
Назначение этих функций состоит в последовательном вычислении своих аргументов. В качестве
результата функция PROG1 возращает значение первого аргумента,
функция PROG2 - первого аргумента, а функция PROGN - последнего
аргумента.
Описываемая тройка функций отличается от функции PROG двумя моментами:
функции PROG1, PROG2 и PROGN не создают локальных
переменных;
в теле функций PROG1, PROG2 и PROGN нельзя
использовать функции GO и RETURN (функции задают последовательное вычисление
аргументов).
Вот примеры, поясняющие все сказанное:
(let ((a 0) (b 0) (c 0)) (prog1 (setq a 111) (setq b 222) (setq c 333)))
==> 111
(let ((a 0) (b 0) (c 0)) (prog2 (setq a 111) (setq b 222) (setq c 333)))
==> 222
(let ((a 0) (b 0) (c 0)) (progn (setq a 111) (setq b 222) (setq c 333)))
==> 333
|
Красным выделены формы, значения которых возвращет соответствующая функция.
|
|
|
|
|
|
|
|
Функция PROPLIST выводит выводит список свойств
значения своего единственного аргумента. Значение
аргумента функции должно быть атомом. Если это не так,
возникает ошибка.
Здесь следует сказать несколько слов о том, что представляет
собой список свойств. Понятие свойства является первичным.
Наличие свойства означает наличие некоторого признака (или
группы признаков). Например свойство "быть числом" или "быть
целым числом". Свойства можно разделить на встроеные и
создаваемые пользователем.
Свойства быть числом, битовой константой, функцией типа
EXPR и т.д - встроенные. Когда в системе
создается атом-константа (числовая или строковая)
соответствующее свойство назначается ему автоматически. Когда
создается переменная (вызовом SET/SETQ), то в случае,
когда значение переменной есть числовая или строковая
константа, соответствующее свойство назначается и переменой. То
же самое имеет место, когда создается константа (вызовом
CSETQ); в дополнение к типу константы добавляется еще
свойство "быть константой (иметь определяющее выражение)".
Каждое свойство идентифицируется (обозначается) атомом - ведь
в Лиспе нет ничего, кроме атомов и списков! Каждому встроенному
свойству соответствует атом: BITS, FIXED, FLOAT, STRING,
EXPR, FEXPR, MACRO, SUBR, FSUBR, APVAL.
Если свойство описывает единственный признак двоичного толка
(есть/нет), то какое свойство называется флагом.
Если же свойство не является двоичным, то для его полного
описания недостаточно одного атома: нужно обозначить
наличие свойства и его значение. В этом случае
атом-идентификатор свойства называется индикатором, а
значением свойства может быть произвольное S-выражение.
Теперь можно объяснить, что представляет собой список
свойств. Это список, существующий для каждого атома, и
включающий все флаги, индикаторы и значения свойств.
Пользователь может создавать свои (произвольные) свойства.
Чтобы создать свойство, сначало нужно создать
атом-идентификатор. А затем добавить его в список свойств (если
это флаг) или добавить в список свойств этот
атом-индикатор и S-выражение, задающее значение
свойства. Разумеется, список свойств может быть и пустым.
Функции, предназначенные для манипулирования индикаторами и
флагами приводятся в описании библиотеки дополнительных
функций. Из всех функций, обслуживающих список свойств, только
две (PROPLIST и SPROPL) являются функциями типа
SUBR; остальные реализованы на HomeLisp-е
Следует отметить, что пользователь может установить в списке
свойств атома стандартный флаг, только присвоив атому
значение соответствующего типа (превратив атом в переменную или
константу). В HomeLisp стандартные флаги не хранятся в
виде списка; они составляют битовую шкалу, хранящуюся в
информационной ячейке атома. Функция PROPLIST строит
список, в котором перечислены стандартные флаги атома (если они
есть), а затем - нестандартные флаги, индикаторы и свойства. В
общем случае не существует способа отличить пару флагов (т.е.
два атома, идущие в списке свойств подряд) от индикатора и
свойства, представляющее собой атом.
Примеры работы с функцией PROPLIST:
(proplist 'h)
==> Nil
(proplist (+ 1 2))
==> (FIXED)
(setq h 111)
==> 111
(proplist 'h)
==> (FIXED)
(spropl 'h '(i1 (1 2 3) i2 (4 5 6) i3 (a b c d)))
==> (i1 (1 2 3) i2 (4 5 6) i3 (a b c d))
(proplist 'h)
==> (FIXED i1 (1 2 3) i2 (4 5 6) i3 (a b c d))
(getprop 'h 'i1)
==> (1 2 3)
(getprop 'h 'i2)
==> (4 5 6)
(getprop 'h 'i3)
==> (a b c d)
(getprop 'h 'i4)
==> NIL
(getprop 'h FIXED)
==> FIXED
|
У только что созданного атома h список свойств пуст.
Результат вычисления (+ 1 2) равен атому 3; его
список свойств состоит из единственного атома FIXED.
После присвоения атому h значения 111 (типа
FIXED), атом h наследует этот флаг. Далее, с
помощью встроенной функции SPROPL атому h в
дополнение к стандартному флагу устаналиваются три
нестандартных свойства: i1 со значением (1 2 3);
i2 со значением (4 5 6); и, наконец, i3 со
значением (a b c d). Вызов PROPLIST позволяет
увидеть весь список свойств - сначала в нем идут стандартные
флаги, а затем пользовательские свойства. Опросить наличие
отдельных свойств можно с помощью функции GETPROP.
Видно, что свойства i1, i2, i3 у атома
h имеются, а свойство i4 - нет. Кстати, отсюда
следует, что нежелательно использовать значение
свойства, равное Nil: нет способа отличить такое
значение свойства от отсутствия свойства (в обоих случаях
GETPROP возвращает Nil).
|
|
|
|
|
|
|
|
Функция PUTD (отсутствующая у Лаврова и Силагадзе) позволяет заменить тело
функции новым. Функция PUTD не является необходимой, - всегда можно переопределить
функцию, вызвав SEXPR/SFEXPR/DEFUN. Разработчик ввел функцию PUTD, руководствуясь
только соображениями симметрии (есть GETD - пусть будет и PUTD!).
Как пользоваться функцией PUTD? Функция принадлежит классу FSUBR - ее аргументы
не вычисляются. Первым аргументом функции должен быть атом-имя функции, тело которой будет
изменено. Вторым параметром должен быть список, состоящий из двух списков: первый - новый
список аргументов функции, второй - новое тело функции.
Примеры работы с функцией PUTD:
(defun f1 (x) (+ x x x))
==> f1
(f1 5 5 5)
==> 15
(proplist f1)
==> (EXPR)
(putd f1 ((x) (* x x x)))
==> ((x)(TIMES x x x))
(f1 5)
==> 125
(proplist f1)
==> (EXPR)
(putd f1 '((x y) (* x y)))
==> ((x y)(TIMES x y))
(f1 6 7)
==> 42
(proplist f1)
==> (EXPR)
|
Сначала создана функция одного аргумента, которая утраивает его значение. Далее,
вызовом PUTD функция модифицирована: теперь она возводит значение своего
единственного аргумента в куб. И, наконец, функция становится функцией двух аргументов,
которая возвращает произведение значений аргументов. Следует при этом отметить,
что тип функции посредством вызова PUTD изменить нельзя, менять можно
только список аргументов и тело. Из приведенного выше примера видно, что список свойств
функции при манипуляциях посредством PUTD не меняется.
|
|
|
|
|
|
|
|
Функция PUTEL (отсутствующая у Лаврова и Силагадзе) позволяет заменить элемент списка, заданного значением
первого аргумента другим значением. Функция ожидает три параметра: модифицируемый список, номер заменяемого элемента и
новое значение заменяемого элемента. При успешном завершении функция возвращает модифицированный список. Если
значение номера элемента превышает длину верхнего уровня списка, функция возвращает атом OutOfRange.
Вот примеры работы с функцией PUTEL:
(putEl '(a b c) 2 '(1 2 3))
==> (a (1 2 3) c)
(putEl '(a b c) 4 'd)
==> OutOfRange
(putEl '(a b c) -3 'f)
PUTEL: Значение номера элемента неположительно
==> ERRSTATE
(setq z '(1 2 3))
==> (1 2 3)
(putEl z 2 -2)
==> (1 -2 3)
Z
==> (1 -2 3)
|
Следует отметить, что функция PUTEL имеет побочный эффект - она модифицирует список
заданный значением первого аргумента (именно поэтому переменная z при последнем вызове меняет
свое значение).
|
|
|
|
|
|
|
|
Функция QUOTE - классическая (и, вероятно, самая странная для понимания новичка) функция Лиспа.
Эта функция на самом деле не делает ничего, она просто блокирует вычисление своего единственного
аргумента (который может быть любым мыслимым S-выражением). Название функции, вероятно, происходит
от английского to quote - брать в кавычки. В классическом Лиспе вызов QUOTE записывается
в виде (QUOTE нечто). В современных версиях Лиспа (и в HomeLisp) эта запись полностью
эквивалентна записи 'нечто. Не следует путать апостроф с двойной кавычкой.
Примеры работы с функцией QUOTE:
(setq a 777)
==> 777
a
==> 777
(quote a)
==> a
'a
==> a
''a
==> (QUOTE a)
(eval a)
==> 777
(eval 'a)
==> 777
(eval ''a)
==> a
|
Первый вызов создает переменную a с числовым значением 777. Ввод S-выражения,
состоящего из атома a вызывает его вычисление. При этом печатается значение атома
a, равное 777. Вызов (quote a), или, что то же самое, 'a приводит
к блокировке вычисления значения a. Результат равен атому a. Следующий пример
показывает двойное квотирование - запись ''a полностью эквивалентна записи
(quote (quote a)). Результат, естественно, равен (quote a). В общем, функция
QUOTE возвращает свой аргумент "как есть" без вычисления.
Для читателей, знакомых
с языком Бэйсик, совершенно ясно, что операторы Print a и Print "a" означают
разные действия: первый оператор печатает значение переменной a,
а второй - букву (символ) a. Примерно так же действует в Лиспе описываемая функция
QUOTE.
Два следующих примера могут вызвать недоумение. Выше отмечалось, что функция EVAL
противоположна функции QUOTE - их действия "взаимно уничтожаются". Понятно, что
результат вычисления (eval a) должен быть равен значению атома a (т.е. 777).
Но результат вычисления (eval 'a) должен быть равен a, не так ли? А результат
снова равен 777... Дело здесь в том, что когда пользователь вводит S-выражение, оно всегда
передается на вход EVAL (при вводе (eval 'a) реально вычисляется
(eval (eval 'a))); таким образом количество вызовов EVAL
оказывается на единицу больше, и это приводит к вычислению значения a.
В последнем примере количество EVAL и QUOTE сбалансировано, что приводит
к ожидаемому результату. Поучительно запросить дамп и сравнить протоколы вычисления последнего
и предпоследнего примеров. Ниже показан протокол вычисления выражения: (eval a)
.EVAL вход: (EVAL (QUOTE a))
..APPLY вход: A1= EVAL A2= ((QUOTE a))
...EVFUN вход: A1= EVAL A2= ((QUOTE a))
...
... Ассоциативный список:
...
... 1 -> (a . 777)
...
....LIST вход: A= ((QUOTE a))
.....EVAL вход: (QUOTE a)
......APPLY вход: A1= QUOTE A2= (a)
.......EVFUN вход: A1= QUOTE A2= (a)
.......
....... Ассоциативный список:
.......
....... 1 -> (a . 777)
.......
.......EVFUN выход: a
......APPLY выход: a
.....EVAL выход: a
....LIST выход: Рез= (a)
....EVAL вход: a
.....EVATOM вход: a
.....EVATOM выход: 777
....EVAL выход: 777
...EVFUN выход: 777
..APPLY выход: 777
.EVAL выход: 777
|
А вот протокол вычисления выражения (eval ''a):
.EVAL вход: (EVAL (QUOTE (QUOTE a)))
..APPLY вход: A1= EVAL A2= ((QUOTE (QUOTE a)))
...EVFUN вход: A1= EVAL A2= ((QUOTE (QUOTE a)))
...
... Ассоциативный список:
...
... 1 -> (a . 777)
...
....LIST вход: A= ((QUOTE (QUOTE a)))
.....EVAL вход: (QUOTE (QUOTE a))
......APPLY вход: A1= QUOTE A2= ((QUOTE a))
.......EVFUN вход: A1= QUOTE A2= ((QUOTE a))
.......
....... Ассоциативный список:
.......
....... 1 -> (a . 777)
.......
.......EVFUN выход: (QUOTE a)
......APPLY выход: (QUOTE a)
.....EVAL выход: (QUOTE a)
....LIST выход: Рез= ((QUOTE a))
....EVAL вход: (QUOTE a)
.....APPLY вход: A1= QUOTE A2= (a)
......EVFUN вход: A1= QUOTE A2= (a)
......
...... Ассоциативный список:
......
...... 1 -> (a . 777)
......
......EVFUN выход: a
.....APPLY выход: a
....EVAL выход: a
...EVFUN выход: a
..APPLY выход: a
.EVAL выход: a
|
Пусть читатель сравнит первые строки этих протоколов (выделены красным цветом). Все станет
ясным.
|
|
|
|
|
|
|
|
Функция QUOTIENT вычисляет частное целочисленного деления значения первого аргумента
на значение второго. Для краткости выражение (QUOTIENT a b) может быть записано в виде
(\ a b). Значения обоих аргументов функции QUOTIENT должны иметь тип FIXED.
Примеры работы с функцией QUOTIENT:
(\ 666 222)
==> 3
(\ 6 3.0)
==> Второй аргумент QUOTIENT - не число FIXED
(\ 6 7 8)
==> Более 2-х аргументов у QUOTIENT
(\ 7 5)
==> 1
(\ 5 7)
==> 0
|
|
|
|
|
|
|
|
|
Функция REMAINDER вычисляет остаток от целочисленного деления значения первого аргумента
на значение второго. Для краткости выражение (REMAINDER a b) может быть записано в виде
(% a b). Значения обоих аргументов функции REMAINDER должны иметь тип FIXED.
Примеры работы с функцией REMAINDER:
(% 666 333)
==> 0
(% 6 4)
==> 2
(% 6 4.0)
==> Второй аргумент REMAINDER - не число FIXED
(% 7 9)
==> 7
(% 7 9 7)
==> Более 2-х аргументов у REMAINDER
|
|
|
|
|
|
|
|
|
Функция RETURN реализована в обеих редакциях ядра HomeLisp, но область
использования этой функции несколько различается.
В 11-й редакции ядра
функцию RETURN допустимо вызывать только находясь в теле PROG. Она
возвращает значение своего единственного аргумента в качестве результата вычисления
функции PROG. Если имеет место вложенность функций PROG, то вызов RETURN
обеспечивает возврат только на один уровень вверх (подобно тому, как в Бэйсике оператор
EXIT FOR обеспечивает выход только из самого внутреннего цикла.
Следует отметить, что если вычисление тела PROG завершается вызовом функции,
отличной от RETURN, то независимо от результата вычисления этой функции,
PROG вернет значение Nil.
Примеры работы с функцией RETURN:
(PROG (i s) (setq s 0.00)
(setq i 0)
A (setq s (+ s i))
(setq i (+ i 1))
(cond ((lessp i 101) (go A))
( T (return s))
)
)
==> 5050.0
(PROG (i s) (setq s 0.00)
(setq i 0)
A (setq s (+ s i))
(setq i (+ i 1))
(cond ((lessp i 101) (go A))
(T (print s))
)
)
5050.0
==> Nil
(PROG (i s) (setq s 0.00)
(setq i 0)
A (setq s (+ s i))
(setq i (+ i 1))
(cond ((lessp i 101) (go A))
(T (prog nil
(terpri)
(print 's=)
(print s)
(terpri)
(return s)
)
)
)
)
s=5050.0
==> NIL
(PROG (i s) (setq s 0.00)
(setq i 0)
A (setq s (+ s i))
(setq i (+ i 1))
(cond ((lessp i 101) (go A))
(T (return (prog nil
(terpri)
(print 's=)
(print s)
(terpri)
(return s)
)
)
)
)
)
s=5050.0
==> 5050.0
|
В качестве примера приводится "лобовое" решение задачи, которую когда-то задал учитель
арифметики маленькому Карлу Гауссу - подсчитать сумму чисел от 1 до 100. Первый пример дает
правильный результат: 5050 (для возврата использована функция RETURN). Во втором
примере результат, накопленный в связанной переменной s, печатается из тела
PROG. Однако, поскольку вызов RETURN отсутствует, функция PROG
возвращает Nil. Третий пример интереснее: хотя в нем использован вызов
RETURN, функция, тем не менее, снова возвращает Nil. Причина заключается
в том, что вызов RETURN выполняется во вложенном вызове PROG (функция
PROG введена для последовательного выполнения вызовов TERPRI, PRINT, TERPRI).
Выход из внешней функции PROG осуществляется без RETURN, - результат
снова Nil. В последнем примере, значение s, возвращемое из функции печати,
тут же "подхватывается" функцией RETURN и обеспечивается корректный возврат значения.
Замечание.
В 13-й редакции ядра функция RETURN может применяться
не только для выхода из PROG-конструкции, но и для досрочного выхода из
циклов, организованных с помощью функций LOOP и DOTIMES. Вот пример решения
задачи подсчета суммы чисел от 1 до 100 с помощью функции LOOP:
(let ((s 0) (i 1))
(loop
(setq s (+ s i))
(setq i (add1 i))
(if (> i 100) (return s))))
==> 5050
|
|
|
|
|
|
|
|
|
Функция RIGHTSHIFT принимает два аргумента. Первый аргумент должен иметь тип BITS,
т.е. быть 32-х битовой логической шкалой. Второй аргумент должен иметь тип FIXED.
Функция возвращает значение первого аргумента, сдвинутое вправо или влево на количество
разрядов, равное модулю значения второго аргумента. При этом, если значение второго аргумента
положительно, сдвиг происходит вправо. При отрицательном значении второго аргумента сдвиг
происходит влево. При сдвиге влево освободившиеся разряды заполняются нулями. При сдвиге
вправо в освободившиеся разряды заносится самый старший разряд. Функция является
"парной" к функции LEFTSHIFT и добавлена в HomeLisp
исключительно по соображениям симметрии.
Примеры вызова RIGHTSHIFT
приводятся ниже:
(rightshift &H77 3)
==> &HE
(rightshift &H77 -3)
==> &H3B8
(rightshift &HEEEEEEEE -3)
==> &H77777770
(rightshift &HEEEEEEEE 3)
==> &HFDDDDDDD
|
|
|
|
|
|
|
|
|
Функция RPLACA принимает два аргумента. Первым аргументом должен быть список или точечная
пара (атом недопустим).
Вторым аргументом может быть произвольное S-выражение. Функция RPLACA заменяет значение
a-указателя значения своего первого аргумента значением второго аргумента. То, что получилось
из значения первого аргумента, возвращается в качестве значения RPLACA. Функция
RPLACA обладает побочным эффектом - после ее вызова могут измениться значения
сразу многих выражений, которые ссылаются на модифицированную ячейку. Но главное коварство
функции RPLACA заключается в том, что с ее помощью можно создавать циклические
списочные структуры. Такие структуры можно нарисовать, но невозможно распечатать.
Рассмотрим сначала элементарные примеры вызова
функции RPLACA:
(setq w '(a . b))
==> (a . b)
(rplaca w 1)
==> (1 . b)
(setq v '((a) b c))
==> ((a) b c)
(rplaca v 'z)
==> (z b c)
|
Видно, что действительно происходит замена первого элемента списка или точечной пары.
Казалось бы подобного эффекта можно достичь с помощью функции CONS. В частности,
Замену атома a точеной пары (a . b) на единицу можно выполнить вот таким вызовом:
(setq w (cons 1 (cdr w)))
Однако вызов с использованием CONS строит новую списочную структуру,
а rplaca модифицирует существующую.
Посмотрим, как с помощью rplaca
можны создавать циклические списки:
(setq w '(a))
==> (a)
(setq w (rplaca w w)
==> (((((((((((((((((((((((...)))))))))))))))))))))))
|
Здесь сначала создан список из одного элемента a. В графическом виде этот список
можно представить так:
|
|
|
Внутреннее представление списка (a)
|
После выполнения вызова (setq w (rplaca w w) a-указатель списочной ячейки будет
указывать на саму списочную ячейку:
|
|
|
Внутреннее представление того же списка после
модификации a-указателя.
|
При печати такой структуры должно быть напечатано сначала бесконечное количества открывающих
скобок, а затем - бесконечное количество закрывающих. В действительности HomeLisp-у
через какое-то время "надоедает" печатать скобки, и выводится просто многоточие...
|
|
|
|
|
|
|
|
Функция RPLACD принимает два аргумента. Первым аргументом должен быть список или точечная
пара (атом недопустим).
Вторым аргументом может быть произвольное S-выражение. Функция RPLACD заменяет значение
d-указателя значения своего первого аргумента значением второго аргумента. То, что получилось
из значения первого аргумента, возвращается в качестве значения RPLACD. Функция
RPLACD (как и RPLACA) обладает побочным эффектом - после ее вызова могут измениться значения
сразу многих выражений, которые ссылаются на модифицированную ячейку. С помощью
функции RPLACD тоже можно создавать циклические
списочные структуры.
Рассмотрим сначала элементарные примеры вызова
функции RPLACD:
(setq w '(a . b))
==> (a . b)
(rplacd w 1)
==> (a . 1)
(setq v '((a) b c))
==> ((a) b c)
(rplaca v 'z)
==> ((a). z)
|
Пусть читатель обратит внимание на то, что во втором примере список превращается в
точечную пару. Почему так происходит станет ясно, если представить значение переменной v
в точечной записи, - оно будет иметь вид: ((a . Nil) . (B . (C . Nil))).
Левая часть этой точечной пары есть (a . Nil), а правая - (B . (C . Nil)).
После выполнения вызова (rplaca v 'z) произойдет замена правой части точечной пары на атом z, результат
будет следующий: ((a . Nil) . z). А это есть в точности ((a) . z).
Аналогичный результат можно было бы получить, сделав вызов:
(setq v (cons (car v) 'z))
Однако вызов с использованием CONS строит новую списочную структуру,
а rplacd (как и rplaca) модифицирует существующую.
Посмотрим, как с помощью rplacd
можны создавать циклические списки:
(setq w '(a b))
==> (a b)
(setq w (rplacd w w)
==> (a a a a a a a a a a a a a a a a a a a a a a ...)
|
Здесь сначала создан список из двух элементов (a b). В графическом виде этот список
можно представить так:
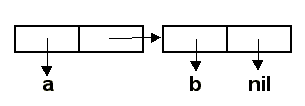
|
|
|
Внутреннее представление списка (a b)
|
После выполнения вызова (setq w (rplacd w w) d-указатель списочной ячейки будет
указывать на саму списочную ячейку:
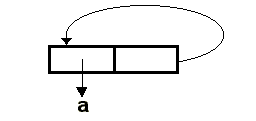
|
|
|
Внутреннее представление того же списка после
модификации d-указателя.
|
При печати такой структуры после открывающей скобки должно быть напечатано бесконечное количество
букв a, а затем - закрывающая скобка.
В действительности HomeLisp-у
через какое-то время "надоедает" печатать одну и ту же букву, и выводится просто многоточие и закрывающая
скобка.
|
|
|
|
|
|
|
|
Функция SET принимает два аргумента. Значением первого аргумента должен быть атом.
Функция создает переменную с именем, равным значению первого аргумента и значением,
равным значению второго. Вторым аргументом может быть произвольное S-выражение. Как отмечалось
выше в разделе, посвященном функции GC, переменные и их значения хранятся в ассоциативном
списке системы. Функция SET в качестве результата возвращает значение второго аргумента.
Рассмотрим примеры вызова функции SET:
(set a b)
==> Символ "a" не имеет значения (не связан).
(set 'a b)
==> Символ "b" не имеет значения (не связан).
(set 'a 'b)
==> b
a
==> b
(set 'c '(1 2 3))
==> (1 2 3)
(set c 777)
==> У функции SET первый аргумент - не атом
(set 'c 777)
==> 777
(set 'xx 'yy)
==> yy
xx
==> yy
(set xx 888)
==> 888
xx
==> yy
yy
==> 888
|
Первые два вызова приводят к ошибке, поскольку Функция SET принадлежит классу
SUBR и оба ее аргумента вычисляются. В этом случае атомы a и b будут
рассматриваться как переменные. Если хотя бы одна из них не имеет значения, возникает
ошибка. Далее создается переменная c, со значением (1 2 3), попытка изменить
значение этой переменной с помощью вызова (set c 777) снова порождает ошибку,
поскольку после вычисления аргументов фактически выполняется некорректная команда
(set (1 2 3) 777). Чтобы изменить значение переменной c, этот аргумент
следует квотировать (как в следующем примере).
Следующая команда присваивает переменной xx значение yy. Казалось бы,
вызов (set xx 888) присваивает переменной xx новое значение
888 (и результат возвращается верный!) Однако, на самом деле у переменной xx значение
остается прежним, а меняется значение переменной yy. Причина та же, что и выше:
после вычисления значения первого аргумента, фактически выполняемый вызов имеет вид:
(set yy 888), и значение меняется у переменной yy (в чем читатель может
убедиться).
Необходимость квотирования первого
аргумента зачастую вызывает неудобство, поэтому чаще применяется функция SETQ,
описываемая ниже.
Следует отметить, что пользователь может изменить значение переменной, но не может
явно ее уничтожить. Исключения составляют связанные переменные функции PROG,
но они уничтожаются (при выходе из PROG) не пользователем, а системой.
Кроме того, если атом является константой (имеет в списке свойств флаг APVAL,
то такой атом не может быть именем переменной. Попытка использовать его в качестве
первого аргумента SET вызовет ошибку:
(csetq a 777)
==> 777
a
==> 777
(proplist 'a)
==> (APVAL FIXED)
(set 'a 888)
==> Попытка превратить константу a в переменную
|
|
|
|
|
|
|
|
|
Функция SETQ, как и функция SET, принимает два
аргумента. Первый аргумент должен быть атомом. Функция
создает переменную с именем, равным первому аргументу (а
не его значению, как SET) и значением, равным значению
второго. Вторым аргументом может быть произвольное S-выражение.
Как отмечалось выше в разделе, посвященном функции GC,
переменные и их значения хранятся в ассоциативном списке
системы. Отличие функции SETQ от функции
SET состоит в том, первый аргумент не вычисляется (и,
следовательно, не нуждается в квотировании). Сама функция
принадлежит к классу FSUBR. Функция SETQ в
качестве результата возвращает значение второго аргумента.
Рассмотрим примеры вызова функции SETQ:
(setq a b)
==> Символ "b" не имеет значения (не связан).
(set a b)
==> b
a
==> b
(setq c '(1 2 3))
==> (1 2 3)
(setq c 777)
==> 777
(setq xx 'yy)
==> yy
xx
==> yy
(setq xx 888)
==> 888
xx
==> 888
|
Сравнивая приведенные примеры с аналогичными примерами для функции SET,
следует признать, что использование SETQ более естественно (поэтому
SETQ и применяется чаще).
Следует отметить, что пользователь может изменить значение переменной, но не может
явно ее уничтожить. Исключения составляют связанные переменные функции PROG,
но они уничтожаются (при выходе из PROG) не пользователем, а системой.
Кроме того, если атом является константой (имеет в списке свойств флаг APVAL,
то такой атом не может быть именем переменной. Попытка использовать его в качестве
первого аргумента SETQ вызовет ошибку:
(csetq a 777)
==> 777
a
==> 777
(proplist 'a)
==> (APVAL FIXED)
(setq a 888)
==> Попытка превратить константу a в переменную
|
|
|
|
|
|
|
|
|
Функция SEXPR предназначена для создания функций
пользователя типа EXPR. Тип EXPR означает, что
все аргументы перед передачей в тело функции вычисляются
(к каждому неявно применяется функция EVAL).
Более просто можно создать функцию с помощью вызова DEFUN.
Функция SEXPR включена в реализацию языка HomeLisp, поскольку
для нее имеется "пара" - функция SFEXPR - средство создания функций
типа FEXPR. DEFUN позволяет создавать только EXPR-функции.
Общий вид конструкции SEXPR приведен ниже:
(sexpr Имя_Функции
(lambda
(...Список_параметров...)
...Тело функции...
)
)
|
Именем функции может быть только атом. Список параметров -
это список атомов - формальных параметров создаваемой функции.
Другое название списка параметров - список связанных
переменных. Тело функции представляет собой S-выражение.
Замечание.
Для 11-й редакции ядра тело функции может содержать
только одно S-выражение.
Для 13-й редакции ядра тело функции может состоять
из произвольного числа S-выражений,
которые вычисляются последовательно. Результатом функции будет результат вычисления
последнего S-выражения.
Эти S-выражения могут использовать переменные из списка параметров
или любые другие переменные (которые называются свободными).
Функция SEXPR связывает имя функции с лямбда выражением.
Если вызов SEXPR корректен, то пользователю становится
доступной новая функция с соответствующим именем, списком
параметров и определяющим выражением. Вызов SEXPR в этом случае возвращает
имя вновь созданной функции.
(sexpr sum3 (lambda (x y z) (+ x y z)))
==> sum3
|
К вновь созданной функции следует обращаться
так: (Имя_функции
...список_фактических_параметров...). Вычисление происходит
следующим образом: сначала создаются переменные в соответствии
со списком формальных параметров, затем каждой из этих
переменных присваивается значение, равное значению
соответствующего элемента списка фактических параметров.
Количество элементов списка формальных параметров и
списка фактических параметров обязаны совпадать (в
противном случае фиксируется ошибка). Этот процесс аналогичен
передаче параметров в процедуру традиционного процедурного
языка.
Далее вычисляется тело функции (определяющее выражение).
Результат вычисления возвращается, как результат функции. Затем
происходит уничтожение связанных переменных в ассоциативном списке.
Для того, чтобы проследить детали вычисления функции, полезно включить
режим дампирования. Вызовем, например, определенную ранее функцию
sum3 следующим образом: (sum3 11 22 33). В дамп-файл
попадет следующая информация:
.EVAL вход: (sum3 11 22 33)
..APPLY вход: A1= sum3 A2= (11 22 33)
...EVFUN вход: A1= sum3 A2= (11 22 33)
....LIST вход: A= (11 22 33)
.....EVAL вход: 11
......EVATOM вход: 11
......EVATOM выход: 11
.....EVAL выход: 11
.....EVAL вход: 22
......EVATOM вход: 22
......EVATOM выход: 22
.....EVAL выход: 22
.....EVAL вход: 33
......EVATOM вход: 33
......EVATOM выход: 33
.....EVAL выход: 33
....LIST выход: Рез= (11 22 33)
....EVLAM вход: A1= ((x y z)(PLUS x y z)) A2= (11 22 33)
.....PAIRLIS вход: ptrAasso=0 A1= (x y z) A2= (11 22 33)
.....
..... Ассоциативный список:
.....
..... 3 -> (z . 33)
..... 2 -> (y . 22)
..... 1 -> (x . 11)
.....
.....PAIRLIS выход: ptrAsso=3
.....EVAL вход: (PLUS x y z)
......APPLY вход: A1= PLUS A2= (x y z)
.......EVFUN вход: A1= PLUS A2= (x y z)
.......
....... Ассоциативный список:
.......
....... 3 -> (z . 33)
....... 2 -> (y . 22)
....... 1 -> (x . 11)
.......
........LIST вход: A= (x y z)
.........EVAL вход: x
..........EVATOM вход: x
..........EVATOM выход: 11
.........EVAL выход: 11
.........EVAL вход: y
..........EVATOM вход: y
..........EVATOM выход: 22
.........EVAL выход: 22
.........EVAL вход: z
..........EVATOM вход: z
..........EVATOM выход: 33
.........EVAL выход: 33
........LIST выход: Рез= (11 22 33)
........PLUS вход: A= (11 22 33)
........PLUS Пром. Рез=11
........PLUS Пром. Рез=33
........PLUS Пром. Рез=66
........PLUS выход: Рез= 66
.......EVFUN выход: 66
......APPLY выход: 66
.....EVAL выход: 66
....EVLAM выход: Рез= 66
...EVFUN выход: 66
..APPLY выход: 66
.EVAL выход: 66
|
Пусть читатель обратит внимание, что в ассоциативном списке образовались
три связаные в теле функции sum3 переменные. Можно убедиться,
что после возврата этих переменных в ассоциативном списке не будет.
(sum3 11 22 33)
==> 66
x
==> Символ "x" не имеет значения (не связан).
|
Если к моменту вызова функции уже имеется свободная переменная, одноименная
со связанной переменной из списка параметров, то в теле функции будет доступно
только значение связанной переменной. После возврата из функции снова будет доступно
прежнее значение свободной переменной. Вот развернутый пример на эту тему:
(sexpr sum3 (lambda (x y z)
(Prog nil
(print 'x=)
(print x)
(terpri)
(print 'y=)
(print y)
(terpri)
(print 'z=)
(print z)
(terpri)
(return (+ x y z))
)
)
)
==> sum3
(setq x 111)
==> 111
(setq y 222)
==> 222
(setq z 333)
==> 333
(sum3 1 2 3)
x=1
y=2
z=3
==> 6
x
==> 111
|
Из этого примера видно, что в теле функции значение, например, переменной x равно 1,
а при выходе восстанавливается прежнее значение 111. Это происходит потому, что при связывании
формальных параметров с фактическими в ассоциативном списке не проверяется существование
переменных с именами из списка формальных параметров. Все новые записи добавляются в конец
списка (а указатель заполнения ассоциативного списка запоминается во внутреннем стеке).
А при запросе значения по имени переменной список просматривается от конца к началу.
Поэтому связанная переменная встретится раньше свободной. Если включить дамп при вычислении
последнего примера, то можно увидеть, как "уживаются" в ассоциативном списке свободные и
связанные переменые:
Начало дампа:
.EVAL вход: (sum3 1 2 3)
..APPLY вход: A1= sum3 A2= (1 2 3)
...EVFUN вход: A1= sum3 A2= (1 2 3)
...
... Ассоциативный список:
...
... 3 -> (z . 333)
... 2 -> (y . 222)
... 1 -> (x . 111)
... ... ...
Вычисление sum3:
....LIST выход: Рез= (1 2 3)
....EVLAM вход: A1= ((x y z)(PROG NIL (PRINT (QUOTE x=))
(PRINT x)
(TERPRI)
(PRINT (QUOTE y=))
(PRINT y)
(TERPRI)
(PRINT (QUOTE z=))
(PRINT z)
(TERPRI)
(RETURN (PLUS x y z))
)
)
A2= (1 2 3)
.....PAIRLIS вход: ptrAasso=3 A1= (x y z) A2= (1 2 3)
.....
..... Ассоциативный список:
.....
..... 6 -> (z . 3)
..... 5 -> (y . 2)
..... 4 -> (x . 1)
..... 3 -> (z . 333)
..... 2 -> (y . 222)
..... 1 -> (x . 111)
|
Если в теле функции потребуется получить значение, скажем, y, то, поскольку просмотр
списка идет от шестого элемента к первому, то сначала встретится пара (y.2). Значение
y будет равно 2.
Замечание.
В 13-й редакции ядра для переменных,
входящих в список параметров функции, при вызове создается лексический
контекст. Дамп вычисления функции sum3, приведеный выше, в
13-й редакции ядра будет выглядеть по-другому:
.EVAL вход: (sum3 111 222 333)
..APPLY_ вход: A1=sum3 A2=(111 222 333)
...EVFUN вход: A1=sum3 A2=(111 222 333)
...
...Лексический контекст:
...
...NIL
...
...Глобальный контекст:
...
...NIL
...
....LIST вход: A=(111 222 333)
.....EVAL вход: 111
......EVATOM вход: 111
......EVATOM выход: 111
.....EVAL выход: 111
.....EVAL вход: 222
......EVATOM вход: 222
......EVATOM выход: 222
.....EVAL выход: 222
.....EVAL вход: 333
......EVATOM вход: 333
......EVATOM выход: 333
.....EVAL выход: 333
....LIST выход: Рез=(111 222 333)
....EVLAM вход: A1=((x y z) (+ x y z)) A2=(111 222 333)
.....PAIRLIS вход: A1=(x y z) A2=(111 222 333) Flg=
.....
.....Лексический контекст:
.....
.....NIL
.....
.....Глобальный контекст:
.....
.....NIL
.....
.....PAIRLIS Выход:
.....
.....Лексический контекст:
.....
.....((z 333) (y 222) (x 111))
.....
.....Глобальный контекст:
.....
.....NIL
.....
.....EVAL вход: (+ x y z)
......APPLY_ вход: A1=+ A2=(x y z)
.......EVFUN вход: A1=+ A2=(x y z)
.......
.......Лексический контекст:
.......
.......((z 333) (y 222) (x 111))
.......
.......Глобальный контекст:
.......
.......NIL
.......
........LIST вход: A=(x y z)
.........EVAL вход: x
..........EVATOM вход: x
...........ASSOC вход: a1 = x
...........
...........Лексический контекст:
...........
...........((z 333) (y 222) (x 111))
...........
...........Глобальный контекст:
...........
...........NIL
...........
...........Assoc выход: 111
..........EVATOM выход: 111
.........EVAL выход: 111
.........EVAL вход: y
..........EVATOM вход: y
...........ASSOC вход: a1 = y
...........
...........Лексический контекст:
...........
...........((z 333) (y 222) (x 111))
...........
...........Глобальный контекст:
...........
...........NIL
...........
...........Assoc выход: 222
..........EVATOM выход: 222
.........EVAL выход: 222
.........EVAL вход: z
..........EVATOM вход: z
...........ASSOC вход: a1 = z
...........
...........Лексический контекст:
...........
...........((z 333) (y 222) (x 111))
...........
...........Глобальный контекст:
...........
...........NIL
...........
...........Assoc выход: 333
..........EVATOM выход: 333
.........EVAL выход: 333
........LIST выход: Рез=(111 222 333)
........PLUS вход: A=(111 222 333)
........PLUS Пром. Рез=111
........PLUS Пром. Рез=333
........PLUS Пром. Рез=666
........PLUS выход: Рез=666
.......EVFUN выход: 666
......APPLY_ выход: 666
.....EVAL выход: 666
....EVLAM выход: Рез=666
...EVFUN выход: 666
..APPLY_ выход: 666
.EVAL выход: 666
|
Если существуют глобальные переменные, одноименные с параметрами некоторой функции,
то в качестве значений будут взяты значения параметров, а не глобальных переменных.
Глобальные переменные располагаются в глобальном контексте, а параметры - в лексическом.
При определении значения символа сначала просматривается текущий лексический контекст,
и только потом - глобальный. Если в дополнение к определению функции sum3 завести
три глобальные переменные x, y и z:
(setq x -111)
==> -111
Создана глобальная переменная x
(setq y -222)
==> -222
Создана глобальная переменная y
(setq z -333)
==> -333
Создана глобальная переменная z
|
а затем вычислить (sum3 111 222 333) с дампированием, то пользователь
увидит:
.EVAL вход: (sum3 111 222 333)
..APPLY_ вход: A1=sum3 A2=(111 222 333)
...EVFUN вход: A1=sum3 A2=(111 222 333)
...
...Лексический контекст:
...
...NIL
...
...Глобальный контекст:
...
...((z -333) (y -222) (x -111))
...
....LIST вход: A=(111 222 333)
.....EVAL вход: 111
......EVATOM вход: 111
......EVATOM выход: 111
.....EVAL выход: 111
.....EVAL вход: 222
......EVATOM вход: 222
......EVATOM выход: 222
.....EVAL выход: 222
.....EVAL вход: 333
......EVATOM вход: 333
......EVATOM выход: 333
.....EVAL выход: 333
....LIST выход: Рез=(111 222 333)
....EVLAM вход: A1=((x y z) (+ x y z)) A2=(111 222 333)
.....PAIRLIS вход: A1=(x y z) A2=(111 222 333) Flg=
.....
.....Лексический контекст:
.....
.....NIL
.....
.....Глобальный контекст:
.....
.....((z -333) (y -222) (x -111))
.....
.....PAIRLIS Выход:
.....
.....Лексический контекст:
.....
.....((z 333) (y 222) (x 111))
.....
.....Глобальный контекст:
.....
.....((z -333) (y -222) (x -111))
.....
.....EVAL вход: (+ x y z)
......APPLY_ вход: A1=+ A2=(x y z)
.......EVFUN вход: A1=+ A2=(x y z)
.......
.......Лексический контекст:
.......
.......((z 333) (y 222) (x 111))
.......
.......Глобальный контекст:
.......
.......((z -333) (y -222) (x -111))
.......
........LIST вход: A=(x y z)
.........EVAL вход: x
..........EVATOM вход: x
...........ASSOC вход: a1 = x
...........
...........Лексический контекст:
...........
...........((z 333) (y 222) (x 111))
...........
...........Глобальный контекст:
...........
...........((z -333) (y -222) (x -111))
...........
...........Assoc выход: 111
..........EVATOM выход: 111
.........EVAL выход: 111
.........EVAL вход: y
..........EVATOM вход: y
...........ASSOC вход: a1 = y
...........
...........Лексический контекст:
...........
...........((z 333) (y 222) (x 111))
...........
...........Глобальный контекст:
...........
...........((z -333) (y -222) (x -111))
...........
...........Assoc выход: 222
..........EVATOM выход: 222
.........EVAL выход: 222
.........EVAL вход: z
..........EVATOM вход: z
...........ASSOC вход: a1 = z
...........
...........Лексический контекст:
...........
...........((z 333) (y 222) (x 111))
...........
...........Глобальный контекст:
...........
...........((z -333) (y -222) (x -111))
...........
...........Assoc выход: 333
..........EVATOM выход: 333
.........EVAL выход: 333
........LIST выход: Рез=(111 222 333)
........PLUS вход: A=(111 222 333)
........PLUS Пром. Рез=111
........PLUS Пром. Рез=333
........PLUS Пром. Рез=666
........PLUS выход: Рез=666
.......EVFUN выход: 666
......APPLY_ выход: 666
.....EVAL выход: 666
....EVLAM выход: Рез=666
...EVFUN выход: 666
..APPLY_ выход: 666
.EVAL выход: 666
|
Все сказанное относится к обычным (не функциональным) аргументам. Для функциональных
аргументов (см FUNCTION)
все происходит иначе.
Если же функция меняет значение свободной переменной то оно останется измененнным и после
выхода из функции:
(sexpr sum3 (lambda (x y z)
(Prog nil
(setq aaa 777)
(return (+ x y z))
)
)
)
==> sum3
(setq aaa 111)
==> 111
(sum3 1 2 3)
==> 6
aaa
==> 777
|
Видно, что переменная aaa - свободна. Ее значение меняется в теле функции и после
возврата остается измененным.
Для 13-й редакции ядра предыдущий пример будет работать аналогично. Если свободной
переменной в теле функции присваивается значение, то, при отсутствии одноименной
глобальной переменной, она будет создана, а при наличии такой переменной, последняя
изменит свое значение.
Замечание.
В 13-й редакции ядра функции могут иметь
необязательные, ключевые и
вспомогательные параметры. Допустимы
также функции с неопределенным числом параметров.
|
Необязательные (optional) параметры
|
Для задания функции с необязательными параметрами используется атом-маркер &optional.
В нужном месте списка параметров ставится атом &optional; все элементы
списка, расположенные перед &optional будут задавать обязательные параметры,
а элементы, расположенные после маркера будут задавать необязательные параметры.
Необязательные параметры можно задавать двумя способами:
в виде списков вида (Имя Значение_по_умолчанию)
в виде списка атомов
Во втором случае значением параметра по умолчанию будет Nil. В первом случае
Значение_по_умолчанию может быть формой, которая вычисляется. Важно подчеркнуть,
что в процессе вычисления очередной формы доступны значения параметров (как обязательных,
так и необязательных), стоящих
в списке параметров раньше вычисляемого. Пример функции с одним обязательным параметром
и двумя необязательными:
(defun f (x &optional (y 222) (z 333)) (list x y z))
==> f
(f 111)
==> (111 222 333)
(f)
PairLis: Слишком мало фактических параметров
==> ERRSTATE
(f 111 -222)
==> (111 -222 333)
(f 111 -222 -333)
==> (111 -222 -333)
(f 111 -222 -333 444)
PairLis: Слишком много фактических параметров
==> ERRSTATE
|
В теле функции строится список значений фактических параметров. Если задан единственный
обязательный параметр, то два других получают значения по умолчанию. Попытка вызвать функцию
f без параметров вызывает ошибку. При задании обязательного и одного из необязательных
параметров, а также всех трех параметров, результат получается вполне предсказуемым. Если
же вызвать функцию с числом параметров большим, чем допускается, то возникает ошибка.
Вот пример функции, у которой значение необязательного параметра по умолчанию
является выражением, зависящим от обязательного параметра:
(defun g (x &optional (y (* x x))) (varlist) (list x y))
==> g
(g 6)
+---------------------+---------+-----------+
| Имя переменной | Тип | Значение |
+---------------------+---------+-----------+
|y |Лексич. |36 |
|x |Лексич. |6 |
+---------------------+---------+-----------+
==> (6 36)
(g 6 8)
+---------------------+---------+-----------+
| Имя переменной | Тип | Значение |
+---------------------+---------+-----------+
|y |Лексич. |8 |
|x |Лексич. |6 |
+---------------------+---------+-----------+
==> (6 8)
|
Хорошо видно, что при задании единственного обязательного параметра значением второго
будет квадрат значения первого. Но если второй параметр задан - то его значение и попадет
в результирующий список.
Если все параметры функции нужно сделать необязательными, следует атом &optional
поместить первым в списке формальных параметров.
Функции могут иметь ключевые параметры. Этот тип параметров задатся после списка
необязательных позиционных параметров после атома &key. Задание ключевых
параметров синтаксически похоже на задание необязательных параметров. Отличия
появляются при вызове функции с ключевыми параметрами. При вызове функции с
ключевыми параметрами значение ключевого параметра задается двумя выражениями:
символом-именем параметра и формой, значение которой будет значением параметра.
Символ-имя получается из имени параметра из списка параметров функции добавлением
двоеточия в начало имени.
Значения ключевых параметров при вызове функции вычисляются последовательно слева направо.
При вычислении очередного значения могут быть использованы значения уже вычисленных параметров.
Ключевые параметры являются необязательными. Но если ключевой параметр задается, в его имени
должно присутствовать лидирующее двоеточие. В примере, приведенном выше, попытка задать два
ключевых параметра, как позиционные вызывает ошибку. Польза от ключевых параметров состоит
в том, что необязательно задавать их значения в том порядке, в котором они перечислены в
списке параметров функции. Использование ключевых параметров делает вызов более наглядным.
Рассмотрим пример:
(defun q (x &key (y (* x 2)) (z (* y 3)) ) (varlist) (list x y z))
==> q
(q 1)
+---------------------+---------+----------+
| Имя переменной | Тип | Значение |
+---------------------+---------+----------+
|z |Лексич. |6 |
|y |Лексич. |2 |
|x |Лексич. |1 |
+---------------------+---------+----------+
==> (1 2 6)
(q 1 2 3)
Ключевой параметр 2 без двоеточия
==> ERRSTATE
(q 1 :z 2 :y -1)
+---------------------+---------+----------+
| Имя переменной | Тип | Значение |
+---------------------+---------+----------+
|y |Лексич. |-1 |
|z |Лексич. |2 |
|x |Лексич. |1 |
+---------------------+---------+----------+
==> (1 -1 2)
|
У приведенной выше функции один обязательный позиционный параметр и два
необязательных ключевых параметра.Хорошо видно, что ключевые параметры
могут задаваться в произвольном порядке.
|
Вспомогательные (aux) параметры
|
Если функции нужны рабочие (вспомогательные) переменные, они могут быть заданы в
списке пераметров, после символа &aux. Рабочие переменные при вычислении тела
функции инициализируются значением Nil и могут использоваться наряду с другими
видами параметров.
Вот пример функции со вспомогательными параметрами:
(defun g (x y &aux q w )
(varlist)
(setq q (* x x))
(setq w (* y y))
(varlist)
(list x y q w))
==> g
(g 11 22)
+---------------------+---------+----------+
| Имя переменной | Тип | Значение |
+---------------------+---------+----------+
|w |Лексич. |NIL |
|q |Лексич. |NIL |
|y |Лексич. |22 |
|x |Лексич. |11 |
+---------------------+---------+----------+
+---------------------+---------+----------+
| Имя переменной | Тип | Значение |
+---------------------+---------+----------+
|w |Лексич. |484 |
|q |Лексич. |121 |
|y |Лексич. |22 |
|x |Лексич. |11 |
+---------------------+---------+----------+
==> (11 22 121 484)
|
Здесь у функци g два вспомогательных параметра. Пример, впрочем, несколько искуственный
(без вспомогательных параметров в данном случае можно было бы легко обойтись).
Конструкция "&aux список_символов" должна быть последней в списке параметров.
|
Функции с неопределенным числом параметров
|
Допустимы функции с неопределенным числом параметров. Чтобы функция могла обработать
неопределенное число индивидуальных параметров, необходимо в конце списка параметров
употребить конструкцию "&rest атом". При вычислении значений параметров после
обработки обязательных и необязательных параметров (в т.ч. и ключевых) все остальные
элементы списка фактических параметров группируются в один список и связываются с символом,
стоящим после символа &rest.
Ниже приведен пример функции с неопределенным числом параметров:
(defun uparm (x &rest y) (cons x y))
==> uparm
(uparm 1 2 3 4 5)
==> (1 2 3 4 5)
(uparm '(1 2 3) 2 3 4 5 6 7 8 9)
==> ((1 2 3) 2 3 4 5 6 7 8 9)
|
Здесь у функции uparm один параметр обязательный (x), а остальные параметры
собираются в список и присваиваются параметру y. Важно подчеркнуть, что конструкция
"&rest символ" должна быть последней в списке параметров.Отсюда следует, что в
HomeLisp нельзя одновременно использовать "&aux список_символов" и "&rest символ".
|
|
|
|
|
|
|
|
Функция SFEXPR предназначена для создания функций
пользователя типа FEXPR. Тип FEXPR означает, что
ни один аргумент перед передачей в тело функции не вычисляется.
Общий вид конструкции SEXPR приведен ниже:
(sfexpr Имя_Функции
(lambda
(...Список_параметров...)
...Тело функции...
)
)
|
Именем функции может быть только атом. Список параметров -
это список атомов - формальных параметров создаваемой функции.
Другое название списка параметров - список связанных
переменных. Тело функции представляет собой S-выражение. Это
S-выражение может использовать переменные из списка параметров
или любые другие переменные (которые называются свободными).
Функция SFEXPR связывает имя функции с лямбда выражением.
Если вызов SFEXPR корректен, то пользователю становится
доступной новая функция с соответствующим именем, списком
параметров и определяющим выражением. Вызов SFEXPR в этом случае возвращает
имя вновь созданной функции.
(sfexpr sum3f (lambda (x y z) (+ x y z)))
==> sum3f
|
К вновь созданной функции следует обращаться
так: (Имя_функции
...список_фактических_параметров...). Вычисление происходит
следующим образом: сначала создаются переменные в соответствии
со списком формальных параметров, затем каждой из этих
переменных присваивается значение, равное
соответствующему элементу списка фактических параметров.
В отличие от функций типа EXPR, здесь не происходит вычисления
элементов списка фактических параметров.
Количество элементов списка формальных параметров и
списка фактических параметров обязаны совпадать (в
противном случае фиксируется ошибка). Этот процесс аналогичен
передаче параметров в процедуру традиционного процедурного
языка.
Далее вычисляется тело функции (определяющее выражение).
Результат вычисления возвращается, как результат функции. Затем
происходит уничтожение связанных переменных в ассоциативном списке.
Для того, чтобы проследить детали вычисления функции, полезно включить
режим дампирования. Вызовем, например, определенную ранее функцию
sum3f следующим образом: (sum3f 11 22 33). В дамп-файл
попадет следующая информация:
.EVAL вход: (sum3f 11 22 33)
..APPLY вход: A1= sum3f A2= (11 22 33)
...EVFUN вход: A1= sum3f A2= (11 22 33)
....EVLAM вход: A1= ((x y z)(PLUS x y z)) A2= (11 22 33)
.....PAIRLIS вход: ptrAasso=0 A1= (x y z) A2= (11 22 33)
.....
..... Ассоциативный список:
.....
..... 3 -> (z . 33)
..... 2 -> (y . 22)
..... 1 -> (x . 11)
.....
.....PAIRLIS выход: ptrAsso=3
.....EVAL вход: (PLUS x y z)
......APPLY вход: A1= PLUS A2= (x y z)
.......EVFUN вход: A1= PLUS A2= (x y z)
.......
....... Ассоциативный список:
.......
....... 3 -> (z . 33)
....... 2 -> (y . 22)
....... 1 -> (x . 11)
.......
........LIST вход: A= (x y z)
.........EVAL вход: x
..........EVATOM вход: x
..........EVATOM выход: 11
.........EVAL выход: 11
.........EVAL вход: y
..........EVATOM вход: y
..........EVATOM выход: 22
.........EVAL выход: 22
.........EVAL вход: z
..........EVATOM вход: z
..........EVATOM выход: 33
.........EVAL выход: 33
........LIST выход: Рез= (11 22 33)
........PLUS вход: A= (11 22 33)
........PLUS Пром. Рез=11
........PLUS Пром. Рез=33
........PLUS Пром. Рез=66
........PLUS выход: Рез= 66
.......EVFUN выход: 66
......APPLY выход: 66
.....EVAL выход: 66
....EVLAM выход: Рез= 66
...EVFUN выход: 66
..APPLY выход: 66
.EVAL выход: 66
|
Следует обратить внимание на то, что хотя результат вычисления и совпадает
с результатом вычисления выражения (sum3 11 22 33), введенной выше при
рассмотрении функций типа EXPR, но внутренняя логика вычислений различна.
Фактические параметры сразу передаются на вход PLUS без предварительного
вычисления. Результат совпадает просто потому, что значения аргументов
11, 22 и 33 совпадают с самими аргументами. Попытка вычислить
(sum3f (+ 10 1) (+ 20 2) (+ 30 3)) вызвала бы ошибку:
Один из аргументов PLUS - не атом
В остальном логика вычисления функции типа EXPR и FEXPR совпадает:
можно убедиться что в ассоциативном списке образовались
три связаные в теле функции sum3f переменные. После возврата этих переменных
в ассоциативном списке уже не будет.
(sum3f 11 22 33)
==> 66
x
==> Символ "x" не имеет значения (не связан).
|
При вычислении функций типа FEXPR действуют те же правила видимости переменных,
что и для функций типа EXPR.
Если к моменту вызова функции уже имеется свободная переменная, одноименная
со связанной переменной из списка параметров, то в теле функции будет доступно
только значение связанной переменной. После возврата из функции снова будет доступно
прежнее значение свободной переменной. Вот развернутый пример на эту тему:
(sfexpr sum3f (lambda (x y z)
(Prog nil
(print 'x=)
(print x)
(terpri)
(print 'y=)
(print y)
(terpri)
(print 'z=)
(print z)
(terpri)
(return (+ x y z))
)
)
)
==> sum3f
(setq x 111)
==> 111
(setq y 222)
==> 222
(setq z 333)
==> 333
(sum3f 1 2 3)
x=1
y=2
z=3
==> 6
x
==> 111
|
Из этого примера видно, что в теле функции значение, например, переменной x равно 1,
а при выходе восстанавливается прежнее значение 111. Это происходит потому, что при связывании
формальных параметров с фактическими в ассоциативном списке не проверяется существование
переменных с именами из списка формальных параметров. Все новые записи добавляются в конец
списка (а указатель заполнения ассоциативного списка запоминается во внутреннем стеке).
А при запросе значения по имени переменной список просматривается от конца к началу.
Поэтому связанная переменная встретится раньше свободной. Если включить дамп при вычислении
последнего примера, то можно увидеть, как "уживаются" в ассоциативном списке свободные и
связанные переменые:
Начало дампа:
.EVAL вход: (sum3f 1 2 3)
..APPLY вход: A1= sum3f A2= (1 2 3)
...EVFUN вход: A1= sum3f A2= (1 2 3)
...
... Ассоциативный список:
...
... 3 -> (z . 222)
... 2 -> (y . 222)
... 1 -> (x . 111)
... ... ...
Вычисление sum3:
....EVLAM вход: A1= ((x y z)(PROG NIL
(PRINT (QUOTE x=))
(PRINT x)
(TERPRI)
(PRINT (QUOTE y=))
(PRINT y)
(TERPRI)
(PRINT (QUOTE z=))
(PRINT z)
(TERPRI)
(RETURN (PLUS x y z))))
A2= (1 2 3)
.....PAIRLIS вход: ptrAasso=3 A1= (x y z) A2= (1 2 3)
.....
..... Ассоциативный список:
.....
..... 6 -> (z . 3)
..... 5 -> (y . 2)
..... 4 -> (x . 1)
..... 3 -> (z . 222)
..... 2 -> (y . 222)
..... 1 -> (x . 111)
.....
.....PAIRLIS выход: ptrAsso=6
|
Если в теле функции потребуется получить значение, скажем, y, то, поскольку просмотр
списка идет от шестого элемента к первому, то сначала встретится пара (y.2). Значение
y будет равно 2.
Если же функция меняет значение свободной переменной то оно останется измененнным и после
выхода из функции:
(sexpr sum3f (lambda (x y z)
(Prog nil
(setq aaa 777)
(return (+ x y z))
)
)
)
==> sum3f
(setq aaa 111)
==> 111
(sum3f 1 2 3)
==> 6
aaa
==> 777
|
Видно, что переменная aaa - свободна. Ее значение
меняется в теле функции и после возврата остается
измененным.
Как отмечалось выше в разделе, посвященном функциональным
аргументам, для функции типа FEXPR при обращении
недопустима конструкция (FUNCTION fff). Чтобы понять
причину запрета, полезно вспомнить как обрабатываются
функциональные аргументы функций типа EXPR.
Если среди аргументов функции типа EXPR встречается
конструкция (FUNCTION fff), она вычисляется до начала
вычисления тела функции. Результатом вычисления является
занесение в ассоциативный список конструкции (f FUNARG fff
n) (где f формальный параметр, соответствующий
фактическому параметру fff, а n - указатель
заполнения ассоциативного списка. Когда процесс исполнения тела
функции дойдет до вычисления (f ...), ассоциативный
список будет уже в другом состоянии (в него могут быть
добавлены другие переменные - в том числе и связанные, но
совпадающие по именам со свободными). Перед началом вычисления
(f ...) в ассоциативный список добавится пара (Nil .
n), где n - число из конструкции (f FUNARG fff
n). Поэтому переменные, содержащиеся в списке между
конструкциями (Nil . n) и (f FUNARG fff n) при
поиске значений обходятся. Именно этот механизм и обеспечивает
корректное использование свободных переменных функциональными
аргументами.
Если же один из аргументов функции типа FEXPR будет
иметь вид (FUNCTION fff), то произойдет совсем другое.
Поскольку аргументы функции типа FEXPR не вычисляются, в
ассоциативный список добавится конструкция (f function
fff) (где f формальный параметр, соответствующий
фактическому параметру fff) и состояние заполнения
ассоциативного списка нигде не зафиксируется. Когда в процессе
исполнения тела функции потребуется вычислить (f ...),
то, поскольку атом f имеет в данном случае значение
(function fff), это выражение вычислится в
неподходящий момент (когда состояние ассоциативного
списка уже изменилось). Поэтому использование конструкции
(FUNCTION f), как аргумента функции типа FEXPR
недопустимо. В HomeLisp попытка использвания аргумента
вида (FUNCTION f) у функции типа FEXPR вызывает
ошибку с диагностикой Недопустимое употребление
FUNCTION.
Все сказанное не означает, что у функций типа FEXPR
не может быть функциональных аргументов. Вот пример функции
типа FEXPR с функциональным аргументом:
(sfexpr sfx (lambda (f x y) (f x y)))
==> sfx
(sfx plus 3 5)
==> 8
(sfx times 3 5)
==> 15
(defun g (x y) (+ (* x x) (* y y)))
==> g
(sfx g 3 4)
==> 25
|
Первый аргумент функции sfx - функциональный.
Соответствующим фактическим параметром вызова в первых двух
примерах являются встроенные функции типа SUBR
(PLUS и TIMES). В последнем примере фактическим
аргументом является функция типа EXPR, которая
подсчитывает сумму квадратов двух своих аргументов. Как можно
убедиться из приведенной выше врезки, все вызовы возвращают
верные результаты. Однако, если попытаться перед вычислением
функционального аргумента использовать в теле функции локальные
переменные, одноименные со свободными, то можно убедиться, что
правило Лиспа не соблюдается - возьмутся активные значения
переменных, а не те, что были в момент вызова функционала.
Пример приводится ниже:
(sfexpr sfx (lambda (f x y) (prog (z) (setq z 3) (return (f x y)))))
==> sfx
(setq z 100)
==> 100
(defun g (x y) (+ z (* x y)))
==> g
(g 3 5)
==> 115
(sfx g 3 5)
==> 18
|
Функция sfx типа FEXPR локализует в своем теле переменную z
и присваивает ей значение 3. Следующая команда создает свободную переменную
z и присваивает ей значение 100. Вновь определенная функция g
вычисляет произведение своих аргументов и прибавляет к нему значение
свободной переменной z. Вызов (g 3 5) возвращает, естественно,
3*5+100=115. При вычислении (sfx g 3 5) используется активное значение
z и получается 3*5+3=18. Предотвратить использование активного значения
z нельзя, т.к. нельзя использовать конструкцию (sfx (function g) 3 5):
(sfx (function g) 3 5)
==> Недопустимое употребление FUNCTION
|
Однако, если ввести соответствующую функцию типа EXPR, то может быть получен
верный результат:
(sexpr sf (lambda (f x y) (prog (z) (setq z 3) (return (f x y)))))
==> sf
(sf (function g) 3 5)
==> 115
|
Функции типа FEXPR используются реже функций типа EXPR. Более
употребительной формой функций типа FEXPR являются функции типа MACRO,
описываемые ниже.
|
|
|
|
|
|
|
|
Функции SMACRO нет в книге Лаврова и Силагадзе (что,
пожалуй, можно считать единственным недостатком этой
замечательной книги!), хотя в Лиспе идея макро
присутствует достаточно давно. В связи с этим, разработчик счел
своим долгом остановиться на идее макро чуть более подробно.
Однако, прежде, чем рассмотреть макро в Лиспе, следует,
вероятно, объяснить, что означает сам термин "макро".
К сожалению, широкое распространение известного популярного
пакета Microsoft Office исказило первоначальный смысл
термина "макро". В терминах Microsoft Office макро (или
макрос) - это программа на языке VBA, которая может быть
написана "вручную" программистом или сгенерирована специальным
средством - макрорекордером. Некоторые горячие головы стали
использовать термин "макро" в уничитижительном смысле,
считая макро не настоящими программами.
В действительности макро - это программный код,
который выполняется во время компиляции программы до ее
перевода на целевой язык. Так, в языках C/C++ макро реализовано
с помощью т.н. препроцессора. Простейший пример макро в языках
C/C++ дается командой #define. Если в тексте программы
встретилась команда:
то везде далее можно употреблять "константу" Pi. Слово
"константа" взято в кавычки не случайно: перед трансляцией
программы в машинный код препроцессор просто заменит все
вхождения лексемы Pi во все выражения языка строкой
символов 3.14159. Этот процесс называется
макро-подстановкой. Так, оператор присвоения:
препроцессор превратит в оператор:
"Константы", введеные командой #define, могут
использоваться для т.н. условной компиляции - в зависимости от
их значения трансляция некоторых блоков кода может обходиться.
Сходные, но менее развитые средства имеются и в Visual Basic.
Этот экскурс был предпринят автором исключительно с целью
показать, что макро в буквальном смысле созданы для
Лиспа! Дело в том, что в Лиспе нет границы между
программами и данными (и то, и другое - списки); поэтому
макро смотрятся в Лиспе естественней, чем в любом другом
языке.
Применительно к Лиспу макро - это функция,
вычисляющая свое тело (или, как говорят, вычисляющая
сама себя).
Макро в Лиспе похожа на функцию типа FEXPR - ее
аргументы не вычисляются. Тело Макро вычисляется в
два этапа: сначала проиходит вычисление
результата аналогично тому, как вычисляется результат функции
типа FEXPR. Результат этого первого этапа можно назвать
макро-расширением; его можно увидеть, вызвав функцию MACROEXPAND. На
втором этапе макрорасширение передается на вход функции
EVAL и вычисляется. Результат вычисления и есть
результат вычисления исходной функции типа Макро.
Рассмотрим простейший пример макро - разработаем
макрофункцию, печатающую S-выражение, заданное первым
аргументом, в числе копий, заданным вторым аргументом. В
соответствии со сказанным выше, эта функция должна
сгенерировать программу для печати заданного S-выражения
нужное число раз. Программа печати должна выглядеть так:
(prog nil
(print s) (terpri)
(print s) (terpri)
... ...
(print s) (terpri)
)
|
Количество строк print - terpri должно быть равно значению
второго параметра - счетчика копий. Один из вариантов функции,
генерирующей такой код, приводится ниже:
(smacro mprint (lambda (stri copies)
(Prog (u z)
(setq u copies)
(setq z '(Prog nil))
loop (setq z (append z (list (list 'print stri))))
(setq z (append z (list (list 'terpri))))
(setq u (- u 1))
(cond ((eq u 0) (return z))
(t (go loop))
)
)
)
)
|
В локальной переменной z образуется нужное S-выражение
(которое сразу же исполняется). Легко убедиться, что функция
mprint работает:
(mprint '(a b c) 5)
(a b c)
(a b c)
(a b c)
(a b c)
(a b c)
==> Nil
|
При желании можно увидеть макрорасширение mprint:
(macroexpand mprint '(a b c) 5)
==> (PROG NIL (PRINT (QUOTE (a b c)))(TERPRI)
(PRINT (QUOTE (a b c)))(TERPRI)
(PRINT (QUOTE (a b c)))(TERPRI)
)
|
Этот пример может показаться бесполезным - того же эффекта проще
добиться обычной функцией типа EXPR:
(defun eprint (stri copies) (prog (i)
(setq i copies)
loop (print stri)
(terpri)
(setq i (sub1 i))
(cond ((greaterp i 0) (go loop)))
)
)
==> eprint
(eprint '(a b c) 6)
(a b c)
(a b c)
(a b c)
(a b c)
(a b c)
(a b c)
==> NIL
|
Не следует, однако, торопиться с выводами. Рассмотрим,
следуя двухтомнику Э. Хювенен и И. Сеппянен [6],
следующую функцию:
(sfexpr pushf (lambda (a p) (setq p (cons a (eval p)))))
==> pushf
|
Эта функция использует линейный список, как стек. Она добавляет свой
первый аргумент в начало списка. Функция вполне успешно работает:
(setq st '(b a))
==> (b a)
(pushf c st)
==> (c b a)
|
Теперь попробуем создать стек с именем p и
добавить в него элемент посредством pushf:
(setq p '(2 1))
==> (2 1)
(pushf 3 p)
==> (3 . p)
|
Функция работает неверно. В чем причина? В том,
что имя переменной-стека совпадает с именем связанной
переменной p. Поскольку переменная p входит в
список формальных параметров функции pushf, ее
внешнее значение в теле функции недоступно. При входе в
функцию pushf переменная p (теперь локальная)
получает значение, равное атому p, а переменная
a - атому 3. Вычисление выражения (cons a
(eval p)) дает в результате точечную пару (3 .
p). Все это отчетливо видно в дампе:
.EVAL вход: (pushf 3 p)
..APPLY вход: A1= pushf A2= (3 p)
...EVFUN вход: A1= pushf A2= (3 p)
...
... Ассоциативный список:
...
... 2 -> (p 2 1)
... 1 -> (st b c)
...
....EVLAM вход: A1= ((a p)(SETQ p (CONS a (EVAL p)))) A2= (3 p)
.....PAIRLIS вход: ptrAasso=2 A1= (a p) A2= (3 p)
.....
..... Ассоциативный список:
.....
..... 4 -> (p . p)
..... 3 -> (a . 3)
..... 2 -> (p 2 1)
..... 1 -> (st b c)
.....
.....PAIRLIS выход: ptrAsso=4
.....EVAL вход: (SETQ p (CONS a (EVAL p)))
......APPLY вход: A1= SETQ A2= (p (CONS a (EVAL p)))
.......EVFUN вход: A1= SETQ A2= (p (CONS a (EVAL p)))
.......
....... Ассоциативный список:
.......
....... 4 -> (p . p)
....... 3 -> (a . 3)
....... 2 -> (p 2 1)
....... 1 -> (st b c)
.......
........SETQ вход: A= (p (CONS a (EVAL p)))
.........EVAL вход: (CONS a (EVAL p))
..........APPLY вход: A1= CONS A2= (a (EVAL p))
...........EVFUN вход: A1= CONS A2= (a (EVAL p))
...........
........... Ассоциативный список:
...........
........... 4 -> (p . p)
........... 3 -> (a . 3)
........... 2 -> (p 2 1)
........... 1 -> (st b c)
...........
............LIST вход: A= (a (EVAL p))
.............EVAL вход: a
..............EVATOM вход: a
..............EVATOM выход: 3
.............EVAL выход: 3
.............EVAL вход: (EVAL p)
..............APPLY вход: A1= EVAL A2= (p)
...............EVFUN вход: A1= EVAL A2= (p)
...............
............... Ассоциативный список:
...............
............... 4 -> (p . p)
............... 3 -> (a . 3)
............... 2 -> (p 2 1)
............... 1 -> (st b c)
...............
................LIST вход: A= (p)
.................EVAL вход: p
..................EVATOM вход: p
..................EVATOM выход: p
.................EVAL выход: p
................LIST выход: Рез= (p)
................EVAL вход: p
.................EVATOM вход: p
.................EVATOM выход: p
................EVAL выход: p
...............EVFUN выход: p
..............APPLY выход: p
.............EVAL выход: p
............LIST выход: Рез= (3 p)
............CONS вход: A1= 3 A2= (p)
............CONS выход: Рез= (3 . p)
...........EVFUN выход: (3 . p)
..........APPLY выход: (3 . p)
.........EVAL выход: (3 . p)
........SETQ выход: Рез= (3 . p)
.......EVFUN выход: (3 . p)
......APPLY выход: (3 . p)
.....EVAL выход: (3 . p)
....EVLAM выход: Рез= (3 . p)
...EVFUN выход: (3 . p)
..APPLY выход: (3 . p)
.EVAL выход: (3 . p)
|
В классическом Лиспе эту проблему решали, просто
используя в качестве формальных параметров экзотические
атомы типа *1 или %1. Использование
макро решает проблему радикально:
(smacro pushm (lambda (a p) (list 'setq p (list 'cons a p))))
==> pushm
(pushm 3 p)
==> (3 2 1)
|
Эта функция работает верно, поскольку связи между
формальными и фактическими параметрами действуют только в
процессе макрорасширения. При вычислении результата
макрорасширения становятся вновь доступны все свободные
переменные.
Пусть читатель обратит внимание еще на одно важное
обстоятельство. Казалось бы, кто мешает рализовать функцию
pushm, как функцию класса FEXPR, в которой
строилось то же самое макрорасширение и тут же
вычислялось (функцией EVAL)? Однако такая попытка ничего
не даст. Приводимый ниже пример убеждает в этом.
(sfexpr pushm (lambda (a p) (eval (list 'setq p (list 'cons a p))) ) )
==> pushm
(setq p '(3 2 1))
==> (3 2 1)
(pushm 4 p)
==> (4 . p)
|
Причина - в реализации макро. Если макрорасширение
вычисляется в той же функции посредством вызова EVAL,
все свободные переменные, входящие в список формальных
параметров, остаются "замаскированными". А при использовании
макро, сгенерированное макрорасширение вычисляется, как
говорят, в исходном контексте (когда значения всех
свободных переменых снова доступны). В этом состоит главная
особенность функций, типа SMACRO.
Кстати, по этой же причине попытка вычислить (pushm a
p) вызывает ошибку: Символ a не имеет значания (не
связан). Казалось бы, этого не должно быть - ведь аргументы
SMACRO не вычисляются. Это так, но когда вычисляется
результат макрорасширения, действуют обычные правила
вычисления. Результат макрорасширения вызова (pushm a p)
будет (SETQ p (CONS a p)). Переменная p имеет
значение, а атом a - нет. Сообщение об ощибке,
приведенное выше, возникает не при макрогенерации, а при
вычислении его результата ((SETQ p (CONS a p))). А вот
обращение (pushm 'a p) выполнится без проблем: здесь
результат макрорасширения будет (SETQ p (CONS (QUOTE a)
p)); атом a квотирован и ошибки нет.
Как отмечают Э. Хювенен и И. Сеппянен, макро могут быть и
рекурсивными. Ниже приводится пример рекурсивного макро:
(smacro copym (lambda (x)
(cond ((null x) nil)
(T (list 'cons (list 'quote (car x))
(list 'copym (cdr x)))))))
==> copym
(copym (a b c))
==> (a b c)
|
Следует отметить, что в HomeLisp для рекурсивного
макро вызов MACROEXPAND вернет только первый "каскад"
макрорасширения:
(macroexpand copym (a b c))
==> (CONS (QUOTE a)(copym (b c)))
|
Главное предназначение макро - обогащение базового языка за
счет внесения в него "новых операторов". В подтверждение этой
мысли рассмотрим функцию типа SMACRO, которая реализует
простой цикл FOR. Пусть оператор цикла имеет следующий
вид:
(FOR i Beg End (... Операторы ...))
Здесь i - переменная цикла; Beg - начальное
значение; End - конечное значение. Операторы
представляют собой список вызовов функций Лиспа. Проще всего
реализовать такой оператор с помощью PROG-конструкции:
(PROG Nil
(setq i Beg)
L (... Операторы ...)
(setq i (add1 i))
(cond ((greaterp i End) (Return End))
(go L)
)
|
Поскольку PROG-конструкция должна возвращать
какое-либо значение, принято решение возвращать верхнюю границу
параметра цикла. Для реализации "оператора FOR" можно применить
следующую функцию типа MACRO:
(smacro for
(lambda
(i ibeg iend meat)
(prog (stmt)
(setq stmt (list 'prog nil (list 'setq i ibeg)))
(setq stmt (append stmt (list 'beg_loop)))
(setq stmt (append stmt meat))
(setq stmt (append stmt (list (list 'setq i (list 'add1 i)))))
(setq stmt (append stmt (list (list 'cond (list (list 'greaterp i iend)
(list 'return iend) )))))
(setq stmt (append stmt (list (list 'go 'beg_loop))))
(return stmt)
)
)
)
|
Остается убедиться, что "новый оператор" успешно работает:
(for i 1 10 ((print 'i=) (print i) (terpri)))
i=1
i=2
i=3
i=4
i=5
i=6
i=7
i=8
i=9
i=10
==> 10
|
и даже позволяет делать вложенные циклы:
(for i 1 3
((for j 1 3
((print 'i=)
(print i)
(prints " ")
(print 'j=)
(print j)
(terpri)
)
)
)
)
i=1 j=1
i=1 j=2
i=1 j=3
i=2 j=1
i=2 j=2
i=2 j=3
i=3 j=1
i=3 j=2
i=3 j=3
==> 3
|
|
|
|
|
|
|
|
|
Функция SPECIALP, реализованная только в 13-й
редакции ядра, принимает один обязательный параметр-атом. Функция проверяет, является ли
атом-аргумент динамической переменной. В этом случае функция возвратит T,
в противном случае функция вернет Nil. Динамические переменные называются также
специальными переменными (отсюда и происходит название SPECILP).
Примеры:
(defdyn 'x)
==> x
(specialp 'x)
==> T
(specialp 'y)
==> NIL
|
Здесь создана динамическая (специальная) переменная x. Символ y задает
обычную (лексическую) переменную.
|
|
|
|
|
|
|
|
Функция SPROPL принимает два аргумента. Первый
аргумент должен быть атомом, второй - списком. Функция
устанавливает у атома - первого аргумента новый список свойств,
равным второму аргументу. Старый список свойств уничтожается.
Функция возвращает в качестве значения новый список свойств
атома-первого аргумента без стандартных флагов. Списки свойств
подробно рассмотрены при описании функции PROPLIST.
Здесь следует еще раз отметить, что стандартные индикаторы
(FIXED, FLOAT, BITS, STRING, SUBR, FSUBR, EXPR, FEXPR,
MACRO, WINDOW, FILE) не хранятся в списках свойств
атомов и не могут быть изменены посредством функций SPROPL,
PUTPROP, PUTFLAG. Стандартные индикаторы "появляются" у
атомов, как следствие действий, выполняемых над атомами
(создание переменных, констант, функций). Однако, функция
PROPLIST возвращает полный список свойств атома, в
котором сначала идут стандартные индикаторы, а потом список
свойств, формируемый функцией SPROPL. На приводимой ниже
врезке все это наглядно показано.
(setq a 111)
==> 111
(proplist 'a)
==> (FIXED)
(spropl 'a '(i1 (q w e) j1 (r t y)))
==> (i1 (q w e) j1 (r T y))
(proplist 'a)
==> (FIXED i1 (q w e) j1 (r T y))
(setq a 11.1)
==> 11.1
(proplist 'a)
==> (FLOAT i1 (q w e) j1 (r T y))
|
Пусть читатель обратит внимание на то, что при изменении типа
переменной a с FIXED на FLOAT
автоматически изменился и ее список свойств. Если же атом
используется для создания графического окна или файлового
потока, то старое содержимое списка свойств (если он имелся у
атома) стирается, и заменяется новым:
(setq w 555)
==> 555
(spropl 'w '(i1 (z x c) i2 (v b n)))
==> (i1 (z x c) i2 (v b n))
(proplist 'w)
==> (FIXED i1 (z x c) i2 (v b n))
(grwCreate 'w 300 300 "Мое окно" &H5599AA)
==> w
(proplist 'w)
==> (WINDOW width 300
height 300
title "Мое окно"
backcolor &H5599AA
WINHANDLE 1)
|
После создания графического окна старый список свойств атома
w полностью заменяется новым.
|
|
|
|
|
|
Функция-предикат STRINGP (отсутствующая у Лаврова и
Силагадзе) принимает единственный аргумент. Если этот аргумент
является атомом и имеет тип STRING, функция возвращает
логическую истину (T). В противном случае функция
возвращает Nil. Вот примеры вызова:
(stringp "K")
==> T
(stringp 4)
==> NIL
(stringp '(1 2 3))
==> NIL
|
|
|
|
|
|
|
|
|
Функция STR2FIX (отсутствующая у Лаврова и Силагадзе)
принимает единственный аргумент. Аргумент должен быть атомом и
иметь тип STRING. Функция преобразует значение аргумента
в число типа FIXED. Из значения аргумента выделяется
слева строка максимальной длины, которая представляет
собой корректное представление целого числа со знаком. Это
число возвращается в качестве результата. Лидирующие пробелы в
значении первого аргумента игнорируются. Если строки,
представляющей целое число, не существует, функция возвращает
нуль. Примеры вызова приводятся ниже:
(str2fix "123456")
==> 123456
(str2fix "123.456")
==> 123
(str2fix "123 456")
==> 123
(str2fix "+123456")
==> 123456
(str2fix "-123456")
==> -123456
(str2fix "a-123456")
==> 0
|
Пусть читатель обратит внимание, что десятичная точка
является таким же терминальным символом, как буква или пробел.
|
|
|
|
|
|
|
|
Функция STR2FLO (отсутствующая у Лаврова и
Силагадзе) принимает единственный аргумент. Аргумент должен
быть атомом и иметь тип STRING. Функция преобразует
значение аргумента в число типа FLOAT. Из значения
аргумента выделяется слева строка максимальной длины,
которая представляет собой корректное представление числа c
плавающей точкой. Лидирующие пробелы в значении первого
аргумента игнорируются. Это число возвращается в качестве
результата. Если строки, представляющей вещественное число, не
существует, функция возвращает нуль. Примеры вызова приводятся
ниже:
(str2flo "8.8")
==> 8.8
(str2flo "8.8E12")
==> 8800000000000
(str2flo "8.8D12")
==> 8800000000000
(str2flo "8.8Q12")
==> 8.8
(str2flo "A8.8")
==> 0.0
|
В отличие от описанной выше функции STR2FIX функция
STR2FLO всегда возвращает результат типа FLOAT.
Кроме того, десятичная точка является значимым символом.
|
|
|
|
|
|
|
|
Функция SUB1 принимает единственный аргумент числового типа (FIXED
или FLOAT). Она отнимает единицу от значения аргумента. Тип результата
совпадает с типом аргумента. Примеры:
(SUB1 -7.0)
==> -8.0
(PROPLIST (SUB1 -7.0))
==> (FLOAT)
(SUB1 54)
==> 53
(PROPLIST (SUB1 54))
==> (FIXED)
|
|
|
|
|
|
|
|
|
Функция SWAPEL (отсутствующая у Лаврова и Силагадзе) принимает три аргумента. Значением
первого аргумента должен быть список. Два последующих аргумента (типа FIXED) задают номера
двух элементов этого списка. Если значения номеров положительны и не превышают длины списка,
то элементы меняются местами, а функция возвращает T. В противном случае функция
возвращает атом outOfRange, а список не меняется. Вот примеры вызова SWAPEL:
(setq z '(a b c d e f))
==> (a b c d e f)
(swapel z 3 5)
==> T
z
==> (a b e d c f)
(swapel z 3 10)
==> OutOfRange
|
Функция SWAPEL может быть реализована на Лиспе. Реализация ее в виде функции типа SUBR
преследует исключительно цели эффективности.
|
|
|
|
|
|
|
|
Функция TERPRI не требует аргументов. Она всегда возвращает значение NIL. Функция
обеспечивает вывод данных последующих вызовов PRINT/PRINTS с новой строки. Пусть читатель
сравнит вывод двух приводимых ниже программ:
(prog (i)
(setq i 5)
L (print 'i=)
(print i)
(cond ((eq i 0) (return nil)))
(setq i (sub1 i))
(go L)
)
i=5i=4i=3i=2i=1i=0
==> NIL
(prog (i)
(setq i 5)
L (print 'i=)
(print i)
(terpri)
(cond ((eq i 0) (return nil)))
(setq i (sub1 i))
(go L)
)
i=5
i=4
i=3
i=2
i=1
i=0
==> NIL
|
|
|
|
|
|
|
|
|
Функция TIMES,(вместо TIMES можно писать
*) вычисляет произведение значений своих аргументов,
которых может быть произвольное количество. Тип аргументов
должен быть FIXED или FLOAT. При этом, если среди
аргументов есть хотя бы один аргумент типа FLOAT, то и
результат будет иметь тип FLOAT. Рассмотрим примеры:
(times 1 3 5 7)
==> 105
(* 1 2 3)
==> 6
(* 1 2.0 3)
==> 6.0
|
|
|
|
|
|
|
|
|
Выполнение программы на языке HomeLisp заключается в
последовательном вычислении S-выражений. Если в процессе
вычисления произошла ошибка, то устанавливается внутренний флаг
состояние ошибки. После этого все вызовы главной функции
Лиспа EVAL, помещенные в стек вызовов, завершаются, а в
качестве значения возвращается предопределеный атом
ERRSTATE. Это означает, что любая ошибка гарантированно
вызывает завершение программы. Излишне распростаняться на тему,
что программирование на самом выразительном и мощном языке
превращается в муку, если в языке отсутствуют средства
обработки ошибок.
Функция TRY, (отсутствующая у Лаврова и Силагадзе)
позволяет перехватывать ошибки выполнения. Функция реализует
современную концепцию обработки ошибок. Суть концепции состоит
в том, что выделяется критический участок кода, который
выполняется в составе конструкции:
TRY
Критический участок кода
EXCEPT
Обработчик ошибки
|
Обработчик ошибки - это программный код, который
получит управление в случае, если при выполнении
критического участка произошла ошибка. В современных
языках программирования обработчик ошибок позволяет в
ряде случаев продолжить выполнение критического участка,
исправив некоторые ошибки.
Применительно к Лиспу, критический участок и
обработчик ошибки - это S-выражения. Возможности
обработчика ошибки в HomeLisp скромнее, чем в C++, - он
позволяет сбросить состояние ошибки, выдать сообщение и
продолжить выполнение программы (если оно имеет смысл). Кроме того,
в обработчике ошибок можно получить текст сообщения об ошибке.
Для этого служит функция ERRORMESSAGE.
Функция TRY вызывается следующим образом:
(TRY Критический участок EXCEPT Обработчик)
Рассмотрим примеры:
(setq x 111)
==> 111
(setq z 000)
==> 0
(/ x z)
DIVIDE - деление на нуль
==> ERRSTATE
(try (/ x z) except nil)
==> NIL
(setq z 222)
==> 222
(try (/ x z) except nil)
==> 0.5
|
Здесь созданы две переменные, а затем вычисляется частное,
при делителе, равном нулю. Естественно, возникает ошибка. Если
же вычислить это выражение посредством функции TRY,
то можно предотвратить возникновение ошибки и вернуть в
качестве результата какое-либо значение (в пример - Nil).
Если же делитель не равен нулю, то функция TRY
возвращает правильный результат вычисления.
Критический участок представляет собой S-выражение, и, в
частности - вложенный вызов функции TRY. Приводимый ниже
пример как раз демонстрирует вложенные обработчики ошибок.
// Пример-1
(try
(prog (x y)
(setq x 12)
(setq y 0)
(return (try
(/ x y)
except 'err-1))
)
except 'err-0)
==> err-1
// Пример-2
(try
(prog (x y)
(setq x 12)
(setq t 66)
(return (try
(/ x y)
except 'err-1))
)
except 'err-0)
==> err-0
// Пример-3
(try
(prog (x y)
(setq x 12)
(setq y 3)
(return (try
(/ x y)
except 'err-1))
)
except 'err-0)
==> 4.0
|
Во всех примерах использованы вложенные обработчики ошибок.
Но в первом примере ошибка возникает при делении (в области
действия внутреннего вызова TRY (место ошибки выделено
красным). Срабатывает внутренний обработчик и
возвращается значение 'err-1. Во втором примере ошибка
возникает до деления (при попытке присвоить значение константе
T - место ошибки выделено красным). Срабатывает
внешний обработчик и возвращается значение
'err-0. В последнем примере ошибок не возникает, и
благополучно возвращается верный результат.
|
|
|
|
|
|
|
|
Функция WHEN типа FSUBR (как и "парная" функция UNLESS)
реализована только в 13-й редакции
ядра. Функция обеспечивает условное вычисление. Вызов функции имеет вид:
|
(WHEN условие форма1 форма2 ... формаn)
|
Вычисление функции WHEN начинается с вычисления формы условие. Если
результат отличен от Nil, то последовательно вычисляются формы
форма1 форма2 ... формаn. Результатом вычисления
WHEN является результат вычисления последней формы - формаn.
Если же результат вычисления формы условие есть Nil, то функция
WHEN сразу же возвращает Nil.
Примеры:
(defun f (x y &aux z)
(when (<> x y)
(setq z (list (* x x) (* y y)))
(sumlist z)))
==> f
(f 8 9)
==> 145
(f 5 5)
==> Nil
|
Создана функция f, принимающая два обязательных аргумента,
и, при неравенстве их значений, сначала строится список квадратов
значений аргументов, а затем вычисляется сумма элементов этого списка.
Если же значения аргументов совпадат, то функция WHEN возвращает Nil.
|
|
|
|
|
|
|
|
Функция UNLESS типа FSUBR (как и "парная" функция WHEN)
реализована только в 13-й редакции
ядра. Функция обеспечивает условное вычисление. Вызов функции имеет вид:
|
(UNLESS условие форма1 форма2 ... формаn)
|
Вычисление функции UNLESS начинается с вычисления формы условие. Если
результат есть Nil, то последовательно вычисляются формы
форма1 форма2 ... формаn. Результатом вычисления
WHEN является результат вычисления последней формы - формаn.
Если же результат вычисления формы условие отличен от Nil, то функция
UNLESS сразу же возвращает Nil.
Примеры:
(defun f (x y &aux z)
(unless (<> x y)
(setq z (list (* x x) (* y y)))
(sumlist z)))
==> f
(f 8 9)
==> Nil
(f 5 5)
==> 50
|
Создана функция f, принимающая два обязательных аргумента,
и, при равенстве их значений, сначала строится список квадратов
значений аргументов, а затем вычисляется сумма элементов этого списка.
Если же значения аргументов не совпадат, то функция UNLESS возвращает Nil.
|
|
|
|
|
|
|
|
Функция UNSET принимает единственный аргумент, значением которого должен быть атом. Функция
ищет в ассоциативном списке глобальную переменную (созданную вызовами SET/SETQ) с именем, заданным этим атомом, и уничтожает ее.
Функция не удаляет переменные, связанные в теле функций и локальные PROG-переменные. Попытка удаления
таких переменных посредством вызова UNSET вызывает ошибку. Вот примеры вызова функции UNSET:
(setq z '(1 2 3))
==> (1 2 3)
(assolist)
+-----------------------------------------+----------------------------------+
| Имя переменной | Тип | Значение |
+-------------------------------+---------+----------------------------------+
|z |Глобал. |(1 2 3) |
+-------------------------------+---------+----------------------------------+
==> NIL
(unset 'z)
==> T
(assolist)
Ассоциативный список пуст
(prog (a b) (setq a 111) (setq b 222) (unset 'b) (return a))
UNSET: переменная b не найдена
==> ERRSTATE
(defun f (x y) (unset 'x))
==> f
(f 5 6)
UNSET: переменная x не найдена
==> ERRSTATE
|
Здесь сначала создается глобальная переменная z, отображается состояние ассоциативного
списка, переменная удаляется и вновь отображается состояние ассоциативного списка. Все эти действия
завершаются успешно. Далее делается попытка удалить PROG-переменную; при этом возникает ошибка.
Аналогичная ошибка возникает при попытке удалить переменную, связанную в теле функции f.
|
|
|
|
|
|
|
|
Функция-предикат ZEROP проверяет, является значение ее
единственного аргумента типа FIXED атомом 0; в
этом случае возвращается T. В противном случае
возвращается Nil. При попытке обратиться к предикату с
аргументом, имеющим тип, отличный от FIXED, возникает
ошибка. Вот примеры:
(zerop 1)
==> Nil
(zerop 0)
==> T
(zerop 0.0)
==> Аргумент ZEROP не число FIXED
(zerop (- 1 1))
==> T
|
В последнем примере сначала будет вычислено выражение (- 1
1) и получен результат 0. Далее будет вычисляться
выражение (zerop 0), значение которого равно T.
|
|
|

|
|
|
Сайт создан в системе uCoz | |